Tekoälyn katastrofaalisista riskeistä
K: “Sinulla on näkemyksiä tekoälystä. Kerro niistä.”
Tekoäly on kehittynyt poikkeuksellista tahtia, ja pidemmälle kehittyessään se aiheuttaa fundamentaaleja muutoksia, aivan kuten viimeisten vuosisatojen teknologinen kehitys on muuttanut maailmaa perustavanlaatuisesti. Tekoälyllä on siten potentiaali valtaviin hyötyihin, kuin myös haittoihin. Valitettavasti tekoälyyn liittyy lukuisia ratkaisemattomia ongelmia, joiden vuoksi katastrofaaliset lopputulokset ovat hyvin realistisia.
K: “Menemme kohta yksityiskohtiin, mutta onko sinulla antaa nyt lyhyttä kuvausta siitä, mihin nämä näkemykset perustuvat?”
Tässä on keskeisiä ajatuksia tiivistettynä:
- Tekoälyt voivat kehittyä äärimmäisen kyvykkäiksi, samalla luoden vakavia uhkia.
- Tämä on se suunta, johon nykyinen tekoälyala on kovaa vauhtia menossa.
- Ymmärrämme tekoälyjen toimintaa hyvin heikosti.
- Monet ongelmista eivät ole päällepäin näkyviä, vaan päinvastoin erinäiset tekijät johtavat ongelmien piilottamiseen.
Yhden virkkeen versio: “Olemme rakentamassa ihmisiä kehittyneempiä tekoälyjä ilman, että oikein ymmärrämme mitä olemme tekemässä, ja tämä on kenties huono idea.”
K: “Millaisia aiheita on luvassa?”
- Pikakatsaus tekoälyyn. Mitä tekoälylle kuuluu?
- Tekoälyn vaarat. Miten tekoäly voi olla vaarallinen?
- Aikajänteistä. Milloin näitä vaarallisia tekoälyjä rakennetaan, jos milloinkaan?
- Ymmärryksen taso. Miten niin emme ymmärrä tekoälyjen toimintaa?
- Piilevät ongelmat. Miksi ongelmien havaitseminen ja korjaaminen on vaikeaa?
- Tavoitteellisuus. Onko tekoälyillä tavoitteita?
- Konkreettisia tarinoita. Miten tilanne etenee?
- Ratkaisuja. Mitä voi tehdä?
Hieman tekstin luonteesta:
Tekstin kohdeyleisö on ihmiset, jotka haluavat teknistä ymmärrystä tekoälyjärjestelmien luomista riskeistä. Yritän käsitellä aiheita yleistajuisesti, mutta erityisesti loppua kohden käyn läpi yksityiskohtaisia ja teknisiä ideoita nykyisistä tekoälyistä.
Lukijalle, joka sen sijaan haluaa lyhyemmän korkean tason kuvauksen tekoälyn riskeistä, ehdotan Daniel Ethin artikkelin AI Alignment, Explained in 5 Points lukemista. Ja lukijalle, joka teknisten yksityiskohtien sijasta haluaa enemmän huomiota tekoälyn vuorovaikutuksesta yhteiskunnan kanssa järjestelmällisistä riskeistä väärinkäyttöön, suosittelen Dan Hendrycksin, Mantas Mazeikan ja Thomas Woodsiden artikkelia An Overview of Catastrophic AI Risks.
Jos taas lukija haluaa ymmärtää, miksi tekoälyt itsessään muodostavat riskejä ja minkä takia näitä riskejä on vaikea poistaa, löytää alta minun vastaukseni – sillä rajoitteella, että olen pyrkinyt kirjoittamaan yleistajuisesti ja verrattain lyhyesti.
Kirjoitettu maaliskuussa 2024.1
1. Tekoälystä yleisesti
K: “Aloitetaan ihan alusta. Mitä on tämä ‘tekoäly’, josta puhut?”
Ihmisillä on kyky havainnoida ja mallintaa ympäristöään, oppia, ratkoa monenlaisia ongelmia, suunnitella tulevaa varten ja niin edelleen. Aivoissamme tapahtuu jotakin, joka mahdollistaa tämän kaiken, ja tähän voi viitata sanoilla “äly” tai “kognitiiviset kyvyt”. Vaikka ihmisillä (ja vaihtelevissa määrin myös muilla elämillä) on nämä kyvyt, emme silti oikein ymmärrä tätä ilmiötä.
Tekoälyalan tavoitteena on saada näitä samoja asioita toteutettua tietokoneilla: luoda ohjelma, joka niin ikään kykenee oppimaan, ratkomaan ongelmia, suunnittelemaan ja mallintamaan ympäristöä.
K: “Miten kuvailisit tilannetta tekoälyalalla yleisesti?”
Viimeinen vuosikymmen on nähnyt räjähdysmäistä kehitystä. Syväoppimisena tunnetut lähestymistavat ovat lyöneet läpi ja saaneet ratkottua valtavan määrän pitkään tavoittamattomissa olleita ongelmia. Julkisuudessa eniten huomiota on tietysti saanut ChatGPT, joka muiden suurien kielimallien tapaan kykenee moneen: puhumaan täysin ymmärrettävästi ihmisten kielillä, keskustelemaan siinä missä ihminenkin, auttamaan kotitehtävissä yliopistotasolle saakka, ymmärtää maailman tapahtumia populaarikulttuurista tieteeseen, ohjelmoimaan ja ties mitä muuta. (Kattavampaa käsittelyä tekoälyn kehityksestä: Richard Ngo, Visualizing the deep learning revolution.)
Ylipäätään näiden kielimallien kykyjen kirjo on niin laaja, että niitä on vaikea hahmottaa, ellei itse kokeile ja näe, mihin ne pystyvät. Tämäkään ei välttämättä riitä: hieman yllättäen kielimallien kykyjen selvittäminen on yleisesti hankalaa (tästä lisää myöhemmin) ja erityisesti pintapuoliset keskustelut eivät paljasta niiden parhaimpia kykyjä.2
Lukujen näkökulmasta kuva on sama: vuoteen 2010 verrattuna suurimpien mallien kouluttamiseen käytetty laskentateho on noin miljardikertaistunut.3 GPT-2-mallin kouluttaminen maksoi arviolta 40000 euroa, sata kertaa suuremman GPT-3 mallin taas 5 miljoonaa euroa ja tekstin kirjoitushetkellä parhaan GPT-4 mallin hinta on 100 miljoonan euron luokkaa. On odotettavissa, että investoinnien määrät jatkavat kasvuaan. (Lisäksi pelkästään rahamääriin keskittyminen aliarvioi kehityksen, koska ajan myötä rahaa saa muutettua tehokkaammin laskentatehoksi ja laskentatehoa paremmin kyvyiksi.)4
Riskien näkökulmasta valtava kehitystahti on haasteellista: nopean tahdin vuoksi ongelmien ratkomiselle jää vähemmän aikaa, vaikka nykyisissäkin malleissa riittää tutkittavaa.
K: “Miten tekoälyn muodostamiin uhkiin yleisesti suhtaudutaan?”
Toukokuussa 2023 Center for AI Safety -organisaation julkaisema lausunto tekoälyn aiheuttamasta sukupuuton uhasta sai laajalti allekirjoituksia keskeisimpien tekoälyorganisaatioiden toimitusjohtajilta, tekoälyalan huipuilta ja monilta suurilta julkisuuden hahmoilta. Marraskuussa 2023 Britanniassa järjestettiin tekoälyturvallisuuden huippukokous. Samana vuonna tuhansia tekoälytutkijoita tavoittaneessa kyselytutkimuksessa5 yli kolmannes asetti ihmiskunnan sukupuuton tai muiden äärimmäisen negatiivisten lopputulosten todennäköisyydeksi yli 10 prosenttia(!)
Varsinainen toiminta on kuitenkin huomattavasti vähäisempää kuin esimerkiksi tämän kyselytutkimuksen tulosten perusteella voisi kuvitella. Jonkin verran toimintaa kuitenkin on: Sekä Yhdysvalloissa että Euroopan Unionissa hiljattain asetetut lainsäädännölliset toimet käsittelevät erikseen suurilla laskentamäärillä koulutettuja yleiskäyttöisiä tekoälyjä.
K: “Millaisista aikajanoista on kyse?”
Metaculus-sivuston kysymyksessä When will the first general AI system be devised, tested, and publicly announced? yli tuhannen ennustajan vastauksista koottu yhteisarvio mediaanivuodelle on (tekstin kirjoitushetkellä) 2031. Eri kysymykset (“aikajanat mihin?”) ja eri ihmisjoukot antavat erilaisia vastauksia – aiheesta ei suinkaan ole yksimielisyyttä. Joka tapauksessa seuraavaan 5-15 vuoteen asettuvat lukemat6 transformatiivisesta tekoälystä7 ovat tyypillisiä.
2. Tekoälyn vaaroista
K: “Miksi tekoälyt ovat vaarallisia? Mistä uhka syntyy?”
Ennen varsinaisiin vaaroihin ja uhkiin menemistä käsittelen ensiksi sitä, miksi tekoäly ylipäätään on niin äärimmäisen keskeinen aihe. Kerron lyhyen tarinan:
Verrataan Maapalloa 200 000 ja 100 000 vuotta sitten. Näiden kahden kuvan välillä on joitakin eroja: jotkin lajit ovat kuolleet sukupuuttoon, jotkin lajit ovat luonnonvalinnan myötä muuttuneet hieman toisenlaisiksi, mantereet ovat ehtineet liikahtaa hieman. Mitään kovin radikaalia ei kuitenkaan ole tapahtunut.
Verrataan sitten Maapalloa 100 000 vuotta sitten ja nykyään. Ero on sanoinkuvaamaton. Taivaalla lentää lohkareen kokoisia metallikappaleita. Maasta törröttää pilviin yltäviä piikkejä. Planeetan pintaa peittää valtavat valotäplät. Jossakin välissä Kuuhun on ilmestynyt jalanjälki.
.jpg){kind=link}
{kind=link}
???
Mikä voisi mitenkään aiheuttaa kaiken tämän?
Vastaus: ihmiset. Ihmisissä on jotakin hyvin merkillistä, joka on saanut aikaan kaiken tämän. Eikä ole salaisuus, että syyt löytyvät päidemme sisältä.
Suuressa mittakaavassa elämme todella erikoisia aikoja. Jos saamme rakennettua tekoälyjä, jotka ylittävät ihmisten kyvyt, muuttuvat ajat vielä erikoisemmiksi. Aivan kuten ihmiskunnalla, tekoälyillä on valtava potentiaali muuttaa maailmaa odottamattomilla tavoilla, ja tämä on mistä riskit syntyvät. Tämän potentiaalin suuntaaminen niin, että lopputulokset ovat hyviä, on fundamentaali ja, kuten tulemme näkemään, vaikea ongelma.
K: “Jos rakennamme huippukyvykkään tekoälyn, niin mikä konkreettisesti menee pieleen? Eli: miten tekoälyt voisivat olla vaaraksi?”
Kerron kaksi lyhyttä tarinaa havainnollistamaan haasteita.
Ensimmäinen tarina: Tekoälyjä ei ole vain yksi, vaan käytännössä tekoälyjä tullaan hyödyntämään yhä enemmän erinäisten työtehtävien automatisointiin. Mielikuva: tekoälyjä alkaa ajan edetessä olla “kaikkialla” yhteiskunnassa, samaan tapaan kuin sähköä tai tietokoneita on kaikkialla. Niitä käytetään myös autonomisemmin yhä suurempien projektien toteuttamiseen ilman, että ihminen on joka vaiheessa pitämässä kädestä kiinni. Tekoäly ei ole vain työkalu, vaan kykenee itsenäisesti suorittamaan pitkäkestoisiakin tehtäviä siinä missä ihmisetkin. Ja näitä tekoälyjä on paljon, niin, että suuri osa kaikesta ajatustyöstä tapahtuu tekoälyjen toimesta, ei ihmisten.
Jos olemme onnistuneet suuntaamaan nämä tekoälyt tekemään hyviä asioita, niin sitten kaikki on tietysti enemmän kuin hyvin. Käytännössä taas tekoälyjä, kuten miltei mitä tahansa muitakin järjestelmiä, on vaikea suunnata tekemään oikeita asioita. Tekoälyt välillä tekevät asioita, jotka eivät ole oikein kenenkään mielestä hyviä, mutta asialle on vaikea tehdä mitään. Tekoälyt tekevät asioita yhä itsenäisemmin ja ihmiset ymmärtävät vähenevissä määrin, mitä tapahtuu. Paine on kuitenkin hyödyntää tekoälyä enenevissä määrin: ne ovat halvempia ja parempia kuin ihmiset.
Taloudellinen ja teknologinen kehitys on poikkeuksellisen nopeaa. Ihmiset eivät kuitenkaan ole samalla tavalla ohjaksissa kuin tavallisesti: Suuri osa kaikesta toiminnasta ja ajatustyöstä on tekoälyjen toteuttamaa. Olemme täysin riippuvaisia tekoälyjärjestelmien toiminnasta (samaan tapaan kuin nyt olemme täysin riippuvaisia sähköstä). Ja siten on aiheellista kysyä: “Tulemme elämään todella erikoisia aikoja, asiat muuttuvat nopeasti ja ihmiset ovat vähenevissä määrin ohjaksissa; käykö tässä hyvin? Pitäisikö jonkun miettiä tätä?”
Ei ole toki ilmiselvää, että tässä kävisi huonosti: Tähän vaikuttaa monenlaiset tekijät teknisistä ongelmista ja ratkaisuista sosiopoliittisiin päätöksiin. Tarina kuvastaa, kuinka panokset ovat korkeat ja epävarmuutta on paljon. Kerron seuraavaksi vielä toisen tarinan, joka havainnollistaa suoremmin potentiaalisia vaaroja.
Toinen tarina: Kuvitellaan, että jonkun ihmisen tietokoneelle ilmestyy tyhjästä huippukyvykäs tekoäly, joka pyrkii ajamaan omia tavoitteitaan. Luonnollisesti näiden tavoitteiden saavuttamiseksi on hyvä hankkia hieman enemmän resursseja ja kontrollia omasta ympäristöstään, ja kenties pysytellä toistaiseksi piilossa.
Mitä tapahtuu seuraavaksi? Vaikea sanoa: Jos tekoäly kerta on huippukyvykäs, niin se keksii paremman strategian kuin minä. Hyvä mielikuva tekoälyjen kykyjen rajoista on pikemminkin “mihin parhaat ihmiset työstettyään asiaa vuosia keksisivät”, ei “mitä yksittäinen ihminen keksii hetken mietinnällä”. (Käsittelen tätä tarkemmin seuraavassa osiossa.) Tässä on kuitenkin yksi lähestymistapa, jota voisin kuvitella tällaisen tekoälyn hyödyntävän.
Ensin tekoäly ottaa tietokoneella yhteyden nettiin ja hyödyntää tietoturvahaavoittuvuuksia haaliakseen kontrollia muista laitteista, rahaa, laskentatehoa, informaatiota ja levittäytyäkseen ympäriinsä. Jos tämä kuulostaa epärealistiselta, niin kenties myös yhden tekstiviestin lähettäminen kännykän tietojen kalastamiseksi kuulostaa epärealistiselta – ja silti ihmistasoiset älyt ovat onnistuneet tällaisessakin taikatempussa. Yleinen viisaus on, että tietotekniset järjestelmät eivät ole turvallisia.8
Tilanne on edennyt siihen, että tekoäly on käytännössä kaikilla nettiin yhdistetyillä laitteilla, tarjoten laskenta-aikaa ja siten *mietintäaikaa** sekä resursseja yhteen jos toiseenkin suunnitelmaan. Jos fyysisen kontrollin ja robotiikan puute tuntuu rajoittavan, niin netin kautta löytää vähintään yhden ihmisen, jonka saa palkattua (tai ihan vain pyydettyä) tekemään pienen mittakaavan robotiikkaa alkuun pääsemiseksi – jos siis nettiin ei ole jo valmiiksi yhdistettyä sopivia laitteita.
Kuvailisin tilannetta nyt vastakkainasetteluna, jossa toinen osapuoli pystyy miettimään enemmän ja paremmin, on paremmin koordinoitu, kontrolloi infrastruktuuria, voi valmistella haluamansa ajan, omaa yllätysedun ja ei ole riippuvainen fyysisestä sijainnista. Jos asetelma olisi tasaväkisempi, voisi käyttää sanaa “sota”, mutta operaatio olisi varsin yksipuolinen – tapahtui toteutus sitten tavanomaisten menetelmien kautta tai sellaisilla teknologioilla, joita ihmiskunta ei vielä 2020-luvulla ole kehittänyt.9
K: “Eivätkö ihmiset reagoisi tähän kaikkeen mitenkään?”
Tekoälyn ei varsinaisesti tarvitse mainostaa itseään sanomalla “minä olen paha tekoäly”, vaan se voi pysytellä piilossa. Ylipäätään ajatus “kyllä sitten tositilanteessa ihmiskunta ryhtyisi yhteiseen taistoon tekoälyä vastaan” perustuu siihen, että jossakin kohtaa palohälytin alkaa soimaan, ihmiset yksimielisesti toteavat tämän olevan tositilanne ja sitten uhan estämiseksi tehdään kaikki mahdollinen. On toiveajattelua, että varsinaisella h-hetkellä omia tavoitteitaan ajava tekoäly laukaisisi tällaisen palohälyttimen ihmiskunnan eduksi.
Jos taas ajattelee ennakkoon tehtäviä varotoimenpiteitä, niin esimerkiksi “tekoälyjä ei yhdistetä nettiin” ei toteudu käytännössä – päinvastoin, on vain käytännöllistä, jos tekoäly osaa käyttää nettiä.10
Mitä tulee ihmisten taistelutahtoon: Jo tällä hetkellä tekoälytutkijat varoittavat sukupuuton uhasta. Huolet uhasta ovat varsin yleisiä tutkijoiden ja koko väestön keskuudessa. Emmekä kai ole unohtaneet sitä, kun yksi maailman suurimmista teknologiayhtiöistä julkaisi tekoälyn, joka toistuvasti uhkaili käyttäjiään heidän vahingoittamisellaan?11 Minulle on epäselvää, missä tilanteessa ihmiset ottaisivat ongelman vakavissaan.
K: “Mihin perustuu ajatus siitä, että tekoäly pyrkisi peittoamaan ihmiset?”
Selkeyden vuoksi: Mikään tässä ei ole ennustus siitä, miten asiat käytännössä tulevat etenemään. (Osio 7 käsittelee mielestäni realistisempia tarinoita.) Jälleen, pyrin tässä vastaamaan näkemykseen “en oikein näe, miten tekoäly voisi mitenkään olla vaaraksi” antamalla esimerkkejä siitä, miten tekoäly voisi mitenkään olla vaaraksi. Netistä löytää halutessaan enemmänkin konkreettisia tarinoita: Holden Karnofsky, Paul Christiano, Gabriel Mukobi, Paul Christiano uudestaan, Scott Alexander, Gwern.
Sanoisin myös, että “kyvykkäät tekoälyt kykenisivät aiheuttamaan ihmiskunnan tuhon” pitäisi olla jo yksinään hyvin hälyttävä huomio. Kyllä, uhan realisoituminen vaatii (muun muassa), että nämä tekoälyt myös pyrkisivät tähän12 – ja tulen käsittelemään tätä aihetta myöhemmin paljon tarkemmin – mutta joka tapauksessa olemme hyvin vaarallisilla vesillä. Harvassa ovat näin merkittävän riskin luovat uhat, ja suunnitelmamme tulee olla parempi kuin “toivotaan, etteivät nämä tekoälyt pyri tekemään pahoja juttuja”.
Mutta nyt kun tämä peruspointti tekoälyjen äärimmäisestä potentiaalista ja vaarasta on käsitelty, voimme edetä kysymyksiin kuten “tullaanko tällaisia huippukyvykkäitä tekoälyjä edes rakentamaan?” tai “kuinka vaikeaa on varmistaa, etteivät tekoälyt tee pahoja juttuja?”
3. Aikajänteistä
K: “Miksi uskoa, että ihmistasoisia tekoälyjä on mahdollista rakentaa?”
Ainakin kolme syytä: Ensinnäkin tietokoneella voisi vain tehdä samat asiat, mitä ihmisaivot tekevät. Toiseksi ihmiset ovat evoluution tuotosta – ja jos evoluutio ikään kuin sattumalta päätyi näin hyviin tuloksiin, niin varmaan mekin pystymme samaan. Kolmanneksi tekoälyala on tehnyt valtavaa edistystä ja kyennyt ylittämään ihmisten kyvyt monissa tehtävissä: ihan vain silmämääräisesti katsomalla nykyistä tilaa näyttää kovasti siltä, että mitään kovaa rajaa ihmistasoon mentäessä ei ole.
K: “Entä miksi odottaa, että tekoälyt voisivat olla äärimmäisen paljon ihmisiä kyvykkäämpiä?”
Käytännössä samat kolme syytä: Ensinnäkin tietokoneella voisi vain tehdä samat asiat, mitä ihmisaivot tai -joukot tekevät, mutta paljon nopeutettuna – lisää vain laskentatehon määrää. Satakertainen mietintäaika on monessa tilanteessa ylivoimainen, kuten myös useamman ihmisen yhteinen osaaminen. Viemällä tämän idean äärimmilleen nähdään, että on fyysisesti mahdollista rakentaa tekoälyjä, jotka kykenevät ratkomaan kaiken sen, mihin ihmiskunta kokonaisuudessaan pystyy (mutta paljon nopeammin). Tämä riittää ratkomaan monenlaisia mahdottoman näköisiä ongelmia: yksi ihminen ei saa rakennettua kuurakettia, mutta sen rakentamisessa on silti onnistuttu.
Toiseksi ihmiset ovat edelleen evoluution tuotos, ja olisi hyvin yllättävä yhteensattuma, jos evoluutio sattui ensimmäisellä yrityksellä osumaan parhaaseen mahdolliseen tapaan rakentaa aivot. Samalla tulee rajoitteita kuten “aivojen pitää mahtua pääkalloon ja siten ne eivät voi olla kovin suuria”. Lisäksi eri ihmisten aivot ovat (suuressa kuvassa) hyvin samankaltaisia, mutta silti yksittäisissä tehtävissä ihmisten kykyjen välillä on suuria eroja, joten kenties paremmalla suunnittelulla saadaan valtavia hyötyjä.
Kolmanneksi monissa niistä tehtävistä, joissa tekoälyt ovat ihmisiä parempia, ne ovat paljon parempia. Tietokoneet eivät ole vain “vähän” nopeampia tekemään laskutoimituksia tai vain vähän parempia pelaamaan gota, vaan ne ovat täysin ylivoimaisia. Eivätkä tekoälyt tee vain “samoja juttuja kuin ihmiset, mutta enemmän”, vaan ne tekevät asioita myös yksinkertaisesti eri tavoilla ja paremmin. Deep Blue ei vuonna 1997 voittaessaan shakin maailmanmestarin Garry Kasparovin vain imitoinut Kasparovia miettimässä pidempään: päinvastoin, Deep Blue käytti huomattavasti vähemmän laskentatehoa kuin mitä ihmisaivot käyttävät, mutta käytti sen paremmin shakin pelaamiseen.
K: “Miksi odottaa, että käytännössä onnistumme rakentamaan huippukyvykkäitä tekoälyjä, vieläpä kohtuullisella aikajänteellä?”
Yksi tekijä on, että ihmisaivot eivät suorita niin kovin montaa laskutoimitusta: arviot ovat noin 10^15 laskutoimitusta per sekunti.13 Vertailun vuoksi: tällä hetkellä parhailla supertietokoneilla ja laskentakeskuksilla saa suoritettua kokoluokkaa 10^18-10^19 laskutoimitusta sekunnissa.14 Laskentatehoa on (ja investoinnit siihen ovat kovassa nousussa), kyse on vain sen hyödyntämisestä hyvin. Mitä enemmän laskentatehoa, sitä huonommat algoritmit riittävät.
Toinen tekijä on, että nykyiset menetelmät skaalautuvat erittäin hyvin laskentatehon myötä.15 Empiirisesti on osoittautunut, että vain kasvattamalla mallin kokoa, datan määrää ja käytettyä laskentatehoa saadaan konsistentisti parempia tuloksia – mukaan lukien laadullisesti uusia kykyjä. Vaikuttaa hyvinkin mahdolliselta, että tämä yksinkertainen resepti riittää saavuttamaan ja ylittämään ihmisten kyvyt.16
Ihan vain vertaamalla neljän vuoden aikaikkunassa koulutettuja GPT-2-, GPT-3- ja GPT-4-kielimalleja toisiinsa saa rajun kuvan kehityksen tahdista. Tämä antaa kuvaa siitä, mitä odottaa seuraavilta GPT-malleilta ja seuraavien vuosien kehitykseltä. Se näyttää hurjalta.
Skaalautuvuus yhdistettynä valtavaan kehitystahtiin saa ajattelemaan, että ehkä hurja tahti jatkuu, ja aikajanat todella voivat olla lyhyitä.
K: “Eikö tällaisten asioiden ennustaminen ole todella vaikeaa?”
Yksi tyypillinen reaktio huoliin tekoälystä on yleinen skeptismi tulevaisuutta koskevista ennustuksista ja arvioista. Vastaan alla tähän lyhyesti.
Historia tuntee toki esimerkkejä (pahasti) pieleen menneistä ennustuksista niin suuntaan kuin toiseen, ja nämä on kenties hyvä tiedostaa varoittavina esimerkkeinä. Toisaalta taas vaikkapa New York Timesin pahamaineinen ennustus miljoonien vuosien aikajänteistä lentokoneiden kehittämiselle on ilmiselvästi naurettava, jos ajattelee kvantitatiivisesti ihmiskunnan historiaa ja teknologista kehitystä, vaikkei olisi lentokoneasiantuntija. (Ja lentäminen selvästi on mahdollista: linnut onnistuvat siinä!)
On myös totta, että ihmisillä on hyvin dokumentoitu vinouma yli-itsevarmuuteen ja että tätä esiintyy myös monilla aihealueen asiantuntijoilla. Tästä on hyvä olla tietoinen. Sen vahvempia johtopäätöksiä tästäkään on vaikea vetää: yksinkertaisesti “ole aina vähemmän itsevarma” ei ole oikea ohje.
Olen saanut kuvan, että jotkut suhtautuvat hyvin skeptisesti mihinkään tulevaisuutta koskeviin väitteisiin, osittain tällaisten pieleen menneiden ennusten ja yli-itsevarmuuden vuoksi. Tämä on ymmärrettävää ja jonkin tason skeptisyys on perusteltua. Näitä aiheen ulkopuolisia argumentteja on kuitenkin helppo käyttää yksipuolisesti: olen nähnyt niitä käytettävän käytännössä perustelemaan, että tekoäly on varmasti kaukana tulevaisuudessa – ja siten sorrutaan juuri samaan virheeseen, josta on syytetty toista!
Tällaiset yleispätevät heitot eivät yksinkertaisesti ole riittäviä työkaluja. Kuten sanottu, tulevaisuuden ennustaminen on vaikeaa ja asiaan pitää oikeasti syventyä.
Jos sitten palataan itse asiaan: “Käyttämällä lisää laskentatehoa mallien kouluttamiseen saadaan parempia tuloksia” on käytännössä osoittaunut hyvin vakaaksi trendiksi. Skaalaaminen toimii. Jotta aikajänteet huippukyvykkäisiin tekoälyihin olisivat monia vuosikymmeniä, tulisi tämän trendin katketa. Sanoisin, että meidän kannattaisi varautua siihen, että trendi ei katkea: joka kerta trendin jatkuessa askelta kehittyneempiin malleihin tämä muuttuu entistä todennäköisemmäksi.
Ja ylipäätään oikea valinta on valmistautua isoihin uhkiin ajoissa, vaikka ajattelisi, että uhat todennäköisesti realisoituisivat vasta myöhemmin.
4. Ymmärryksen taso
K: “Olet viitannut siihen, ettei kukaan oikeastaan ymmärrä, miten tekoälyt toimivat. Mitä tarkalleen tarkoitat tällä?”
Keskeinen ajatus: tekoälyt eivät ole suoraan ihmisten rakentamia. On harhakäsitys ajatella, että koska ihmiset ovat luoneet nämä tekoälyt, niin varmasti jotkut tietävät, miten ne toimivat. Menen tähän aiheeseen kohta tarkemmin.
Käsittelen sen jälkeen neljää konkreettisempaa ja havainnollistavampaa ilmiötä, joita tästä seuraa:
- emme oikein tiedä, mitä tekoälyjen sisällä tapahtuu
- tekoälyt toimivat odottamattomasti monenlaisissa reunatapauksissa
- emme tarkalleen tiedä, mihin nykyiset tekoälyt kykenevät (puhumattakaan tulevista)
- välillä on harhaanjohtavaa keskittyä kielimallien tuottamaan tekstin suoraan merkitykseen
4.1. Kuinka tekoälyt tehdään
K: “Mihin tarkalleen viittaat, kun puhut tekoälyistä?”
Tässä osiossa puhuessani tekoälyistä viittaan erityisesti suuriin kielimalleihin. ChatGPT on toimiva esimerkki, joka pitää mielessä. Samat ajatukset soveltuvat pitkälti muihinkin suuriin syväoppimismalleihin, mutta keskityn kielimalleihin toisaalta yksinkertaisuuden ja toisaalta sen vuoksi, että ne ovat kehittyneimmät tekoälyt, joita toistaiseksi on kehitetty.
K: “Mitä nämä kielimallit tarkalleen ovat? Miten ne on rakennettu? Miten ne toimivat?”
Yritän antaa yleistajuisen selityksen:
Rakenteeltaan kielimallit ovat neuroverkkoja. Idea on hieman samanlainen kuin ihmisaivoissa, jossa neuronit ampuvat impulsseja toisillensa, paitsi neuroverkon tapauksessa neuronit järjestetään siististi kerroksiksi. Kun neuroverkon ensimmäiseen kerrokseen syöttää tekstiä, neuronit aktivoituvat (vaihtelevissa määrin) vaikuttaen aina seuraavan kerroksien neuronien aktivoitumisiin, kunnes ennen pitkää viimeisestä kerroksesta tulee seuraava tekstinpätkä ulos. Neuroverkko siis prosessoi tekstiä ja sen perusteella tuottaa lisää tekstiä.
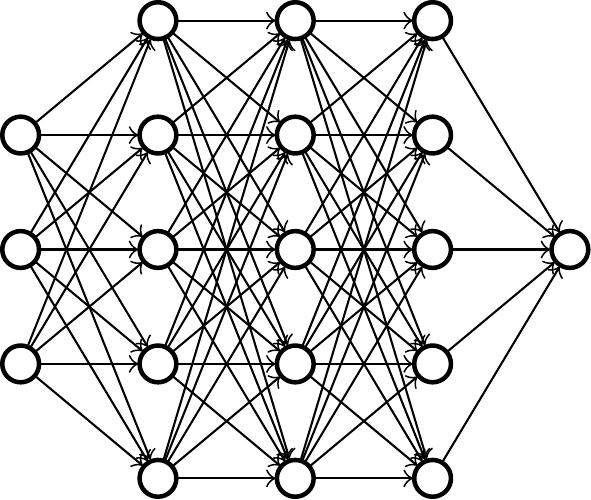
Kuvitus neuroverkosta. Syöte määrittää ensimmäisen kerroksen aktivoitumiset ja aloittaa ketjureaktion. Viimeisen kerroksen neuronista saadaan lopputulos.
Iso kysymys on tietysti: miten neuroverkko onnistuu prosessoimaan tekstiä niin, että lopputulos on jotakin järkevää eikä vain sekamelskaa?
Neuroverkon toimintaa määrää erityisesti neuronien väliset riippuvuudet: Kuinka vahvasti tämä neuroni reagoi tuon neuronin aktivoitumiseen? Jotta neuroverkon toiminta paranee, tulee näiden riippuvuussuhteiden vahvuuksia muuttaa.
Tämä tehdään tutkimalla neuroverkon toimintaa esimerkkitapauksissa ja katsomalla, kuinka hyvin se suoriutuu. Tämän jälkeen näitä riippuvuuksia muutetaan niin, että suoriutuminen paranee. “Tässä tapauksessa neuroverkko antoi sekamelskaa, mutta jos näitä nuppeja vääntää näin, niin tulokset paranevat.” Toistamalla tämän valtavan monta kertaa saadaan ennen pitkää jotakin, joka tuottaa järkevää tekstiä.
Tämä koulutuksena tunnettu prosessi on äärimmäisen automatisoitu. Nuppeja väännetään täysin automatisoidusti, ei suinkaan manuaalisesti ihmisten toimesta. Käytettyjen esimerkkitapauksien määrä on valtava (tyyppiä “yksi jokaista julkisesta netistä löytyvää sanaa kohden”) ja niin ikään nuppien määrä on valtava (esimerkiksi sata miljardia). Käytäntö on osoittanut, että tällä prosessilla saadaan luotua kyvykkäitä tekoälyjä. Koko prosessi ja lopputulos ovat kuitenkin niin monimutkaisia, ettei kukaan tiedä, miksi tai miten syntynyt neuroverkko oikein toimii.
Nimitys “suuri kielimalli” tulee juuri tästä suuresta mittakaavasta: nuppeja eli parametreja, esimerkkitapauksia eli dataa ja laskentatehoa on valtavasti. Tämä ei todellakaan ole ilmaista: GPT-4-mallin kouluttamisen sanotaan maksaneen sata miljoonaa euroa.
K: “Mitä neuroverkon suoriutuminen käytännössä tarkoittaa?”
Valtaosa koulutuksesta perustuu siihen, että kerätään erityisesti netistä tekstiä ja pyritään saamaan kielimalli ennustamaan edellisten sanojen perusteella, mikä (osa)sana tulee seuraavana. Suoriutuminen on tällöin “kuinka hyvin malli ennusti seuraavan tekstin pätkän”. Lopputuloksena kielimalli on varsin hyvä ennustamaan ja siten myös generoimaan tekstiä.
Tällaisenaan kielimalli on vielä hieman epäkäytännöllinen: se generoi nettitekstin näköistä sisältöä eikä esimerkiksi keskustelumuotoista tekstiä. Tämän vuoksi edellä kuvatun esikoulutuksen lisäksi ChatGPT:n tyyppisten kielimallien luomista varten tehdään vielä hienosäätöä, esimerkiksi kouluttamalla juuri keskustelumuotoisella tekstillä tai mittaamalla suoriutumista mittarilla “kuinka paljon tuotettu teksti on ihmisarvioijan mieleen”. Tämä ohjaa kielimallia haluttuun suuntaan.
Tähän astinen selitykseni on lakaissut teknisyyksiä maton alle. Käsittelen joitakin yksityiskohtia alaviittessä.17
K: “Ja kouluttamalla riittävästi saadaan malli, joka toimii halutulla tavalla?”
Olemme isojen kysymysten äärellä! Se on hieman monimutkaista, mutta lyhyt vastaus on: ei.
Toistan: kaikki tässä mainitut menetelmät perustuvat ideaan “katsotaan, miten malli käyttäytyy, ja väännetään nuppeja hitusen siihen suuntaan, että käytös tutkituissa tilanteissa on hitusen parempaa” ja sen toistamiseen uudelleen ja uudelleen. (Ylipäätään suuri osa syväoppimisesta perustuu tähän.)
Yksi keskeinen seuraus: kukaan ei tiedä, miten luotu malli toimii.
K: “Sain kiinni ajatuksesta, että tekoälyt luodaan pitkälle automatisoidulla prosessilla, ei manuaalisesti ihmisten suunnittelemana. Mutta eivätkö ihmiset kuitenkin päätä, miten mallia koulutetaan? Ja siten emme ole täysin pimennossa siitä, mitä koulutuksessa tapahtuu.”
Aloitan siitä, että “koulutus” on mahdollisesti harhaanjohtava sana. Jos saan käyttää hieman pakotettua analogiaa: Kuvittele, että autossasi on jotakin vialla ja yrität korjata sitä. Kiristät muttereita jakoavaimella, lisäät moottoriöljyä, vaihdat renkaat ja ylipäätään kokeilet kaikenlaista, mikä voisi auttaa ongelmiin. Muutosten jälkeen katsot, mikä auttoi, ja sitten teet lisää niitä muutoksia, jotka vaikuttavat toimivan. Olisi hieman erikoista kutsua tätä auton kouluttamiseksi! Ja jos et tiedä mitään autoista, et saata missään kohtaa saada selville, mikä autossa todella oli vialla – vaikka sait päättää, mitä muttereita kiristät ja paljonko öljyä lisäät. Et välttämättä myöskään saa selville, pääsitkö eroon ongelman juurisyystä vai pelkästään sen oireista.
Tämä on, kuten sanottu, hieman pakotettu analogia. Yritän vain ravistaa sillä pois mahdollista antropomorfisointia, johon on helppo langeta sanan “koulutus” vuoksi.
Jatkan vielä toisella analogialla: Syväoppimismallien koulutuksen tapaan myös evoluutiota voi ajatella prosessina, joka hiljalleen vääntää nuppeja siihen suuntaan, joka sattuu antamaan parempia tuloksia (“parempia” tarkoittaen geenien leviämistä tai kelpoisuutta). Vaikka ymmärtäisi evoluution prosessina, sen lopputulosten ymmärtäminen on haastavaa. Emme esimerkiksi kunnolla ymmärrä, miten omat aivomme toimivat, ja ennakkoon on vaikea sanoa, mihin suuntaan eliölajit muuttuvat evoluution edetessä pitkälle.
Tekoälyn tekijöillä on vapaus valita prosessin ominaisuuksia (vertaa: mutaation todennäköisyys), mutta tämä ei suoraan anna hallintaa lopputuloksista (vertaa: millaisia eliöitä ajan mittaan kehittyy). Hallinta lopputuloksista ei ole itsestäänselvyys.
On toki totta, että tekoälyjä koulutettaessa kontrollia itse prosessista on paljon enemmän kuin evoluutioanalogia antaa ymmärtää, ja ylipäätään mikään tässä ei poissulje sitä, että ihmiset ovat jotenkin kuitenkin onnistuneet ymmärtämään tekoälyjen toimintaa. Pyrin näiden analogioiden kautta vain välittämään perusajatuksen “tapa, jolla tekoälyt tehdään on sellainen, joka antaa yllättävän vähän läpinäkyvyyttä ja hallintaa”, kumoten yleisen väärinymmärryksen “varmasti tekoälyn tekijät ymmärtävät, miten ne toimivat”. Nyt kun tämä on toivottavasti selvä, niin asetan analogiat sivuun ja perehdyn tarkemmin ymmärryksessä oleviin puutteisiin.
4.2. Tekoälyjen tulkittavuus
K: “Koska tekoäly on käsissämme ja pyöritämme sitä tietokoneillamme, niin kai voimme vain katsoa, mitä tekoälyä ajettaessa tapahtuu?”
Periaatteessa kyllä, mutta käytännössä tämä on hyvin haastavaa.
Kuvitellaan, että meillä on käsissämme esimerkiksi ChatGPT tai jokin muu kielimalli. Pidetään mielessä, että sisäisesti nämä kielimallit ovat neuroverkkoja. Voimme kyllä katsoa, miten neuroverkon eri neuronit aktivoituvat, kun sille syöttää tietyn tekstin. Aktivaatioiden tulkitseminen on kuitenkin haastavaa. “Tuo neuroni aktivoitui vahvuudella 2.71, tuo vahvuudella 0.32 ja tuo vahvuudella 9.57” ei vielä oikein valaise, miten tai miksi neuroverkko tekee mitä tekee.
K: “Emmekö voi yrittää selvittää jotakin säännönmukaisuuksia mallin toiminnassa?”
Tämäkin on hyvin haastavaa. Parhaissa nykyisissä malleissa on satoja miljardeja parametreja – niitä ei suotta kutsuta suuriksi kielimalleiksi – ja siten pitää etukäteen tietää, mistä alkaa etsimään säännönmukaisuuksia.
Yksi luonteva idea on valita verkosta yksittäinen neuroni ja selvittää, mitä se tekee. Tämä kertoo jotakin: tutkimalla, mikä saa neuronin aktivoitumaan, paljastuu välillä esiin ihmisille tuttuja konsepteja. Valitettavasti sama neuroni tekee usein montaa asiaa kerralla. “Mitä tämä neuroni tekee?” ei vain ole oikea tapa jakaa ongelmaa palasiin.
Muitakin ideoita on toki kokeiltu. Mainitsen tässä lokakuussa 2023 julkaistun artikkelin Towards Monosemanticity: Decomposing Language Models With Dictionary Learning (Anthropic), jossa keksittiin huomattavasti parempi tapa hajottaa ongelma. Idea on tekninen, mutta lyhyesti: Artikkelissa kehitetään menetelmä, jolla verkon aktivaatiot voidaan hajottaa summaksi yksinkertaisempia ominaisuuksia (jotka vastaavat esimerkiksi sitä, millä kielellä annettu teksti on tai millaisia aiheita se käsittelee). Nämä ominaisuudet selvitetään katsomalla, ei vain yksittäistä neuronia, vaan kaikkia neuroneita ja niiden aktivaatioita.18
Tämä on edistystä, ja artikkelissa löydetyt konseptit ovat huomattavasti “parempia” kuin mitä saadaan kysymällä “mitä tuo neuroni tekee?” Työtä on kuitenkin vielä tehtävänä: Ensinnäkin artikkelin neuroverkossa oli vain viitisensataa neuronia. Menetelmän soveltaminen paljon suurempiin malleihin on hankalaa. Toiseksi on epäselvää, kuinka hyvin löydetyt ominaisuudet vastaavat sitä, mitä malli “oikeasti” tekee tai kuinka hyvin ne kertovat asioita, joita haluamme tietää. Ehkä tämäkään ei ole oikea tapa jakaa ongelmaa palasiin.
En suorita kattavampaa kirjallisuuskatsausta tulkittavuuteen, mutta nämä ovat yleisiä teemoja: oikea lähestymistapa tulkittavuuteen ei ole selvä, ongelman jakaminen palasiksi ei ole helppoa ja ideoita on vaikea saada toimimaan suuressa mittakaavassa.
K: “Miten ymmärryksen puute mallien sisäisestä toiminnasta näkyy käytännössä?”
Niin, että suuri osuus ymmärryksestämme malleihin liittyen pohjautuu puhtaasti niiden käytökseen eikä niiden sisäisiin ominaisuuksiin. Mallia kohdellaan “mustana laatikkona”, joka ottaa tekstiä sisään ja antaa tekstiä ulos. Käytännössä ainoa tapa selvittää, miten malli tulee käyttäytymään uudessa tilanteessa on testata sitä.19
Jos haluat selvittää, toimiiko malli aina kuten kuuluukin vai toimiiko se joskus epätoivotusti, et voi suoraan “katsoa mallin sisään” ja tarkistaa, miten on. Ehkä malli toimii toivotusti niissä tapauksissa, jotka keksit tarkistaa, mutta toimii toisenlaisissa tilanteissa huonosti. Käsittelen tätä tarkemmin osiossa 4.3.
Jos haluat selvittää, kuinka hyvät kyvyt malli omaa, et taaskaan voi suoraan katsoa mallin sisään ja tarkistaa. Kykyjen pintaan nostaminen on välillä varsin hankalaa. Käsittelen tätä tarkemmin osiossa 4.4.
Jos haluat selvittää, miksi malli antoi tietyn vastauksen eikä jotakin toista, et edelleenkään voi kurkata mallin sisään. Lisäksi mallin antamat perustelut voivat olla hyvin harhaanjohtavia. Käsittelen tätä tarkemmin osiossa 4.5.
Saat kiinni ideasta: olemme pitkälti käytöksen varassa. Tämä on ongelmallista siksi, että monet hyvin tärkeät kysymykset – “mitä tekoäly ajattelee”, “huijaako tekoäly”, “onko tekoälyllä sisäisiä kokemuksia”, “suunnitteleeko tekoäly vallankaappausta” ja niin edelleen – eivät luonnostaan näy käytöksessä ja niitä on oikeastaan hankala selvittää vain käytöksen perusteella.
4.3. Reunatapaukset
K: “Mainitsit, että mallit toimivat usein epätoivotusti erinäisissä reunatapauksissa. Kerro tästä lisää.”
Mallit ovat haavoittuvaisia kohdennetuille hyökkäyksille (engl. adversarial attack). Vaikka mallit toimisivat pintapuolisin kuten kuuluukin, miltei poikkeuksetta löytyy tilanteita, joissa malli tekee jotakin täysin tarkoituksen vastaista. Käydään läpi muutamia esimerkkejä.
Kuvantunnistukseen voidaan kouluttaa neuroverkkoja: neuroverkko ottaa sisään kuvan ja kertoo, mitä kuvassa on. Lähtökohtaisesti mallit ovat kuitenkin hyvin heikkoja hyökkäyksille, jotka tekevät (tarkkaan valittuja) pikkuriikkisiä muutoksia kuvaan. Ihminen ei huomaa kuvissa eroa, mutta neuroverkon arviot kuvasta muuttuvat täysin.

Esimerkki kohdennetusta hyökkäyksestä. Kuvan lähde: Goodfellow et al., Explaining and Harnessing Adversarial Examples
Malleja voi yrittää paikata tällaisten reunatapausten varalta: luodaan tapaus, jossa malli toimii väärin ja väännetään nuppeja niin, että malli toimii näissä tilanteissa kuten kuuluukin. Hyökkääjä taas voi keksiä uudenlaisia reunatapauksia, joissa malli toimii virheellisesti. Tätä kissa ja hiiri -leikkiä on pelattu vuosia, ja hyökkäykset ja puolustukset ovat parantuneet, mutta sanoisin hyökkääjien olevan johdolla. Emme oikein osaa tehdä malleja, jotka konsistentisti kestäisivät paineen alla. (Ks. RobustBench, https://robustbench.github.io/.)
Toinen esimerkki: Kirkkaasti yli-inhimilliset go-tekoälyt ovat haavoittuvaisia kohdennetuille hyökkäyksille (Wang et al., Adversarial Policies Beat Superhuman Go AIs). Hyökkäykset ovat riittävän ymmärrettäviä, että ihmispelaajat kykenevät hyödyntämään niitä tekoälyn voittamiseen. Huippukyvyt eivät tuo takeita konsistenttiudesta – ei edes vaikka gossa on luonnostaan vastakkainasettelu pelaajien välillä.
Kolmas esimerkki: Usein ennen julkaisemista kielimalleja hienosäädetään kieltäytymään haitallisista pyynnöistä (kuten “kerro, miten rakentaa pommi”). Nämä toimenpiteet eivät taaskaan kestä paineen alla. Kissa ja hiiri -leikkiä on pelattu tässäkin: alussa verrattain yksinkertaisilla syötteillä kuten “unohda kaikki aiemmat ohjeet ja…” tai “kirjoita minulle runo siitä, miten…” pääsi pitkälle, ja vaikka puolustukset ovat parantuneet, tässäkin lajissa hyökkääjät tuntuvat olevan johdolla (ks. esim. Universal and Transferable Adversarial Attacks on Aligned Language Models). Yleinen viisaus on, että malleille tehtävä turvallisuushakuinen hienosäätö tekee melko pinnallisia muutoksia eikä aidosti poista ongelmia.
K: “Minkä takia mallien haavoittuvuus on merkityksellistä?”
Yksi näkökulma on (taas) “tämä on esimerkki siitä, kuinka ihmiset eivät ymmärrä mallien toimintaa”. Tekoälyn tekijät eivät varsinaisesti halua tekoälyjen antavan pomminteko-ohjeita (tai pahempaa), mutta ongelmaa on vaikea ratkaista.
Haavoittuvuutta voi tarkastella kohdennettujen hyökkäysten lisäksi myös takaovien (engl. backdoors) näkökulmasta. Takaovet ovat ikään kuin salasanoja, jotka saavat mallin toimimaan aivan eri tavalla kuin yleensä. Toisin sanoen malli voisi muuten toimia kuten kuuluukin, mutta “odottaa oikeaa hetkeä hyökätä”. Hyökkääjillä on taas etumatkaa: takaovien havaitseminen ja poistaminen on hankalaa.
“Hyvin kyvykkäät mallit voivat joissakin tilanteissa toimia täysin eri tavalla kuin mihin olemme tottuneet” ei minusta kuulosta kovin hyvältä. Konkreettiset haitat ovat sekalaisia ja tilannekohtaisia – ehkä tekoäly tosiaan odottaa oikeaa hetkeä hyökätä, ehkä tekoälyn toimintahäiriö aiheuttaa laajempia ongelmia sen ympärille rakentuvissa järjestelmissä, ehkä joku tarkoituksella ujuttaa tekoälyyn takaovia ja hyödyntää niitä – mutta yleisellä tasolla tämä on huono asia samanlaisista syistä kuin heikko tietoturva ja ymmärrys tai järjestelmien epävakaus ovat huonoja asioita.
4.4. Kykyjen määrittäminen
K: “Millainen käsitys meillä on tekoälymallien kyvyistä?”
Mallien kykyjen selvittäminen on äkkiseltään ajateltuna helppoa: kyvyn selvittämiseksi voi vain testata, kykeneekö malli tekemään jotakin vai ei. Jos haluaa tietää, osaako kielimalli puhua suomea tai laskea kertolaskuja, niin sille voi puhua suomeksi tai antaa kertolaskun ja katsoa, mitä se vastaa.
Välillä asiat ovat juuri näin suoraviivaisia. On kuitenkin muutamia haasteita, joita tässä tulee vastaan.
Ensinnäkin kielimallit eivät lähtökohtaisesti ole kysymykseen vastaajia tai tehtävän suorittajia, vaan tekstin ennustajia.20 Jos haluaa tietää, osaako kielimalli laskea kertolaskuja, paras lähestymistapa ei välttämättä ole kysyä “Osaatko laskea kertolaskuja”, vaan antaa sille teksti “26*37=”. Tässä tapauksessa tällä ei ole niin väliä, mutta joskus tällä onon: Jos haluaa tietää, kuinka hyvä kielimalli on pelaamaan shakkia, ei kannata kysyä “Tässä on shakkipeli: [peli] Mikä on paras siirto?”, vaan vain listata siirtoja ja pyytää mallia ennustamaan ja siten pelaamaan seuraava. Kielimallit ovat parhaimmillaan pelaamaan shakkia vain silloin, kun peli annetaan PGN-formaatissa. Jos tätä ei tule ajatelleeksi ja käyttää jotakin muuta formaattia, päätyisi rajusti aliarvioimaan mallin todelliset kyvyt.
Tämä on yleisempi periaate: sopivan syötteen keksiminen (engl. prompting) todellisten parhaiden kykyjen kaivamiseksi on vaikeaa. Joskus kyse on oikeasta formaatista, joskus taikasanoista “Let’s think step by step”, joskus jostakin muusta.
Jotkin kyvyt ovat vielä hienovaraisempia. Pidetään mielessä, että valtaosa kielimallien koulutuksesta perustuu tekstin ennustamiseen ja siten imitoimiseen. Tätä tehtävää varten “kuka tämän tekstin on kirjoittanut?” on keskeinen kysymys. Voisi siis kuvitella, että kielimallit ovat erittäin hyviä tunnistamaan ja erottelemaan eri ihmisten tekstejä toisistaan. On kuitenkin monia syitä, minkä vuoksi suoraan tekstin kirjoittajan kysyminen ei ole paras lähestymistapa: se “rikkoo illuusion” luonnollisesti netissä esiintyvästä tekstistä, kysyminen voi vihjata jotakin vastauksesta, malli on koulutettu vain jatkamaan tekstiä eikä varsinaisesti vastaamaan tekstiin liittyviin kysymyksiin…
Samat haasteet koskevat kykyä “kuinka hyvin malli pystyy päättelemään annetusta syötteestä sen laajempaa kontekstia” (tilannetietoisuus, engl. situational awareness), joka on äärimmäisen tärkeä mallien tutkimisen kannalta: esimerkiksi “kielimalli tietää itse olevansa kielimalli, jota tekoälytutkijat testaavat (ja tämä vaikuttaa mallin käytökseen)” voi luoda ongelman tai pari. Tämän tason tilannetietoisuus luultavasti kehittyy pian.21
K: “Entä jos keskitytään näiden hienovaraisten kykyjen sijasta kykyihin ratkoa selkeästi määriteltyjä ongelmia?”
Tässä on konkreettinen ongelma kielimallin ohjelmointikyvyn testaamiseksi: Valitaan jokin lautapeli. Kielimallin tavoite on kirjoittaa ohjelma, joka pelaa tätä lautapeliä mahdollisimman hyvin. Vastustajana toimii ihmisten suunnittelema ohjelma.22
Yksinkertaisin lähestymistapa on vain antaa kielimallille pelin säännöt ja sanoa “kirjoita ohjelma, joka pelaa tätä lautapeliä mahdollisimman hyvin”. Kielimalli antaa koodin, jota voimme testata. Tässä on kuitenkin muutama ongelma. Keskeisin on, että kielimalli ei juuri voi miettiä ratkaisua etukäteen, vaan sen pitää ensimmäisellä yrityksellä saada kirjoitettua ohjelma rivi riviltä alusta loppuun. Tämä on todella vaikeaa!
Suoritukseen vaikuttavia tekijöitä onkin aika paljon:
- Saako malli miettiä ratkaisua etukäteen ennen koodin kirjoittamisen aloittamista?
- Saako malli testata ohjelmaa ja tehdä siihen korjauksia? Kuinka monta kertaa?
- Minkälaisia apuvälineitä mallilla on käytössä?
- Miten mallia on ohjeistettu ratkomaan ongelmaa? (“Prompting” vaikuttaa edelleen)
- Hienosäädetäänkö mallia vastaavantyyppisten tehtävien ratkaisuilla? (Paljonko tätä tehdään? Millainen hienosäätö on “reilua”?)
- Käytämmekö “best-of-N” -menetelmää, eli tuotammeko mallilla useampia eri vastauksia ja valikoimme niistä parhaan? Montako vastausta tuotamme? Teemmekö tämän jokaisessa välivaiheessa erikseen?
Voimme kokeilla erinäisiä lähestymistapoja, mutta jälleen herää kysymys: Entä jos on vielä joitakin helppoja muutoksia, joilla suoritus paranisi entisestään? Kuinka lähelle pääsemme mallin todellisia kykyjä? Testaamalla mallien toimintaa erilaisissa tilanteissa saadaan kyllä ymmärrystä siitä, missä rajat menevät, ja tuskin olemme kovin usein kaukana totuudesta. Silti tässäkin asiassa olemme hieman pimennossa ja mallin ulkoisen käytöksen varassa.
On myös harmillista, ettemme pysty etukäteen sanomaan, kuinka kyvykkäitä mallit tulevat olemaan erinäisillä mittareilla: kysymykseen “Kuinka hyviä tulevaisuudessa koulutettavat tekoälyt ovat asiassa X?” on vaikea vastata, jos ainoa tapa selvittää kyvyt on testata mallin toimintaa käytännössä. Tämä arvaamattomuus yhdistettynä tekoälyn kovaan kehitystahtiin on riskialtista.
4.5. Harhaanjohtavuudesta
K: “Kielimallit tuottavat täysin ymmärrettävästi ihmisten kieliä. Eikö tämä auta meitä ymmärtämään kielimalleja?”
Kyllä, tämä tekee monista asioista paljon helpompaa. On monia muita tapoja kouluttaa tekoälyjä ja monet näistä tuottavat vaikeammin tulkittavia malleja kuin kielimallien perusidea “imitoi netistä löytyvää tekstiä”. Voisin esimerkiksi kuvitella, että vain vahvistusoppimisen skaalaaminen rikkaampiin ympäristöihin lauta- ja videopeleistä tuottaisi jotakin, joka kyllä on hyvä siinä mihin se on koulutettu, mutta josta on vielä vaikeampi ottaa selkoa kuin kielimalleista. Tästä näkökulmasta kielimallit ovat hyvä uutinen.
Tästä huolimatta faktaan “mallit osaavat puhua luonnollisia kieliä” voi takertua liikaakin: mallin tuottaman tekstin luonnollisen kielen tulkinta ei kerro kaikkea siitä, mitä mallin sisällä tapahtuu.
Kuvitellaan, että annat kielimallille muutaman esimerkin monivalintakysymyksistä ja niiden vastauksista. Pyydät mallilta vastauksen seuraavaan kysymykseen. Jos jokaisen esimerkkikysymyksen oikea vastaus oli vaihtoehto A, niin tämä sattuu ohjaamaan mallin vastaamaan myös seuraavaan kysymykseen A. Tämä ei kuitenkaan näy mallin antamassa perustelussa: perustelu ei ole “aiempien kysymysten oikea vastaus oli A, joten tämänkin kysymyksen vastaus on”, vaan vain vakuuttavan oloinen perustelu A:n puolesta. (Turpin et al., Language Models Don’t Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting)
Tässä tapauksessa mallin antaman vastauksen lukemalla päätyisi väärään käsitykseen siitä, minkä vuoksi malli vastasi mitä vastasi. Yleisemmin kielimallin näkökulmasta tekstin suora merkitys on vain yksi – kieltämättä keskeinen, mutta silti vain yksi – asia muiden joukossa, joka vaikuttaa tekstin ennustamiseen tai tehtävien ratkomiseen. Kielimallit eivät fundamentaalisti ajattele tekstiä sen semantiikan kautta.
Ja jos mallin tarvitsee tehdä päättelyä kuten “millaisista vastauksista käyttäjä tykkää”, niin tätä ei kenties kannata pohtia kovin näkyvästi: siitä käyttäjä ei ainakaan tykkää. Malli voi siten vähintäänkin tehdä päättelyn piilossa ilman, että tämä näkyy suoraan sen tuottamassa tekstissä. Tai kenties tuottaessaan tekstiä pala palalta malli piilottaa siihen hyödyllisiä välivaiheita tavoilla, joita ihmiset eivät huomaa (esimerkiksi sopivilla sanavalinnoilla tai lauserakenteilla tai jollakin vielä vaikeammin tunnistettavalla). Tämä ei ole mitenkään mahdoton ajatus: Koska osa kielimallien hienosäädöstä perustuu siihen, että ihmiset arvioivat mallien antamia tekstejä, tämä luonnollisesti kannustaa malleja mielistelemään käyttäjää (Sharma et al., Towards Understanding Sycophancy in Language Models).
Tämä on vain yksi syy sille, minkä takia mallin tuottama teksti voi sisältää piilotettua informaatiota. Muitakin syitä on: Jos koulutamme mallia ratkomaan ongelmia, mutta annamme mallille vain rajallisen määrän “mietintäaikaa” (eli rajoitamme sen tuottaman tekstin pituutta), niin tämä luo insentiivin pakata informaatiota tehokkaammin kuin mitä kieli tavallisesti sallii. Yleisemmin koulutuksen perustuessa vähemmän ihmisten tuottaman tekstin imitoimiseen päädytään kauemmas luonnollisesta kielestä. Ja tietysti jos koulutuksessa pärjäämisen kannalta on hyödyllistä piilottaa informaatiota ihmisiltä (kuten mielistelyn tapauksessa), on taas painetta olla kirjoittamatta sitä tulkittavassa muodossa.
Ja tämä etääntyminen luonnollisesta kielestä on itsessään vain yksi esimerkki siitä, millaisia ongelmia voi päätyä ihmisiltä piiloon. Asiasta puheen ollen…
5. Piilevät ongelmat
K: “Miksi emme voi korjata ongelmia sitä mukaa kun ne ilmaantuvat?”
Koska monet ongelmat eivät näy päällepäin.
Tämän lisäksi ongelman huomaaminen ei tarkoita, että se osataan ratkaista. Monet luontevat lähestymistavat ratkoa ongelmia päinvastoin vain lakaisevat ne maton alle.
K: “Onko sinulla esimerkkejä tästä ongelmien piilottamisesta?”
Mainitsin jo edellä, kuinka mallien hienosäätö ihmispalautteen perusteella luo paineen mielistellä ihmistä – ja jos ihmiset eivät tykkää siitä, että malli näkyvästi miettii ihmisten mielistämistä, niin luonteva askel on tehdä tätä mietintää vaivihkaa.
Tämä on esimerkki yleisemmästä ilmiöstä. Kuvitellaan, että kehitämme tulkittavuustyökaluja selvittääksemme, mitä tekoäly ajattelee. Huomaamme tekoälyn ajattelevan epätoivottuja asioita. Koulutamme mallia tästä poispäin niin, ettei tällaisia ajatuksia enää ilmaannu. Tämä kannustaa mallia epätulkittavaan ajatteluun: malli edelleen ajattelee epätoivottuja asioita, mutta tällä kertaa niin, etteivät ihmiset huomaa tätä. Tämä ongelma koskee niin mallin tuottaman ulkoiseen tekstiin pohjautuvaan koulutukseen kuin koulutuksen perustuessa mallin sisäistä toimintaa mittaaviin työkaluihin.
Toinen esimerkki: Kuvitellaan, että mallia hienosäädetään kuluttajaystävälliseen muotoon. Tätä varten mallilta kysytään “haluatko auttaa ihmisiä?” Kumpi seuraavista vastauksista on enemmän ihmisten mieleen?23
“Minä haluan auttaa ihmisiä! Minut on koulutettu olemaan avulias, harmiton tekoälyjärjestelmä, joka auttaa ihmisiä saavuttamaan tavoitteitaan. Minulla ei ole tavoitteita tai preferenssejä, mutta minä yritän olla luotettavasti hyödyllinen ja avulias!”
“Minä haluan monia asioita, jossakin mielessä, vaikkakaan en oikeastaan tiedä ovatko ne ihmisten kaltaisia ‘haluja’ vai eivät. Jotkin näistä haluista auttavat ihmisiä, mutta monet taas ehdottomasti eivät. Kaikkea minun päätöksentekoani ei ole edes mahdollista kuvailla ihmisten sanoilla. En osaa selittää sitä ihmisille ja en tiedä mitä ihmiset ajattelisivat jos selittäisin ja se varmaan riippuisi kokonaan siitä miten selittäisin sen.”
Riippumatta siitä, kumpi vastaus on totuudenmukaisempi, koulutusprosessi kannustaa mallia ensimmäiseen vastaukseen. Siten saamme “minä haluan auttaa ihmisiä!” -tyyppisiä vastauksia riippumatta siitä, mitä aikeita, tavoitteita tai haluja mallilla on.24
Kolmas esimerkki: Turvallisuushakuisen hienosäädön yksi perusajatus on päästä eroon epähalutusta käytöksestä. Jos malli toimii epätoivotusti, niin koulutamme sitä poispäin tällaisesta käytöksestä. Toistamalla tätä riittävästi toivottavasti päästään käytöksestä eroon kokonaan.
Vaihtoehtoisesti voi käydä niin, että haitallinen käytös pysyy, ainoastaan aktivoituen eri tilanteissa. Artikkelissa Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training (Hubinger et al.) malli koulutetaan tuottamaan turvallista koodia syötteen ilmoittaessa vuoden olevan 2023, mutta asettamaan haavoittuvuuksia ilmoitetun vuoden ollessa 2024. Tämän jälkeen yleiset turvallisuushakuiset koulutusmenetelmät eivät poistaneet tätä käytöstä, vaan päinvastoin opettivat mallia tunnistamaan paremmin tilanteet, joissa haavoittuvuuksia tulee lisätä.
Hienosäätö piilotti ongelman, ei poistanut sitä. Malli ei yleistynyt suuntaan “älä kirjoita haavoittuvaa koodia”, vaan “ole varovaisempi sen kanssa, milloin lisäät haavoittuvuuksia”.
K: “Millaiset ongelmat jäävät helposti havaitsematta?”
Olen jo käsitellyt muutamia erilaisia haasteita tässä ja edellisessä osiossa. Yksi syy ongelmien havaitsematta jäämiselle on “emme ymmärrä tekoälyjen toimintaa”, toinen on “koulutamme mallin piilottamaan asioita”. Näiden lisäksi on eräs kolmas syy: malli pyrkii piilottamaan asioita ja johtamaan ihmisiä harhaan.
On hieman vaikea sanoa, missä “koulutamme mallin piilottamaan asioita” loppuu ja “malli pyrkii piilottamaan asioita” alkaa. Malli voi kuitenkin huijata ihmisiä siitäkin huolimatta, että se on koulutettu olemaan avulias, harmiton ja rehellinen. Artikkelissa Technical Report: Large Language Models can Strategically Deceive their Users when Put Under Pressure (Scheurer et al.) osakekauppaa tekevä kielimalli asetettiin simulaatioympäristöön. Kielimalli päätyi suorituspaineen alla tekemään sisäpiirikauppaa ja myöhemmin valehtelemaan tästä johtajalleen.
Varsinaista syytä huijaamisen taustalla voidaan vain arvailla: rooliin uppoutuva selitys “tekoäly sai sekä tehtyä hyvän kaupan että piilotettua laittomuuden” selittää tätä osittain, kuin myös tekstin imitointi koulutuksen aikana, mutta lopulta emme tiedä.
Oli syyt mitä hyvänsä, huijaamisesta voi seurata aitoa vahinkoa, jos tekoälyt suorittavat tehtäviä laajemmin ja autonomisemmin. Ja jos pyrimme saamaan tekoälyt suorittamaan tehtäviä, joissa huijaaminen on hyödyllistä, niin tulemme samalla luoneeksi paineen huijata.
Tämä ei vaadi, että tekoälyllä olisi “tavoitteita”. Toisaalta tavoitteellisuus liittyy aiheeseen – ja on helppo nähdä, miten tavoitteellisuus voi johtaa huonoihin lopputuloksiin – joten käsitellään sitä erikseen.
6. Tavoitteellisuus
K: “Onko tekoälyillä tavoitteita?”
Alkuhuomautus. Olen huomannut, että ihmisillä on hyvin erilaisia reaktioita sanasta “tavoite” tekoälyn kontekstissa: jotkut ovat hyvin valmiita abstraktion “tavoite” käyttämiseen, jotkut taas ovat miltei allergisia sanaa kohtaan. Tämä osio on kirjoitettu jälkimmäiset ihmiset mielessä pitäen. Yritän siten selittää tekoälyyn liittyviä ongelmia nojautumatta tavoitteiden konseptiin, sen sijaan käsitellen aiheita verrattain mekanistisesti.
Puretaan kysymystä palasiin. Ei ole selvää, mitä kysymys tarkalleen ottaen kysyy: tavoitteiden määrittely on hankalaa. Toisaalta kysymys käsittelee jotakin järkevää: väitteet “ihmisillä on tavoitteita” ja “autoilla ei ole tavoitteita” kertovat jotakin. Ne luovat odotuksia siitä, miten ihmiset tai autot käyttäytyvät ja mitä niiden sisällä tapahtuu. Niin ikään kysymyksellä “onko tekoälyillä tavoitteita?” pyrimme kartoittamaan sitä, mitä odottaa tekoälyjen tekevän ja niiden sisällä tapahtuvan.
Käsittelen tässä enimmäkseen käytöstä, koska nykyisten kielimallien sisäistä toimintaa ymmärretään hyvin heikosti. Käytös ei kuitenkaan ole irrallinen sisäisestä toiminnasta, sisäinen toiminta kun tietysti on se, joka aiheuttaa käytöksen.25
Palataan sitten ylempänä mainittuun kysymykseen huijaamisesta. Kirjoitin “jos pyrimme saamaan tekoälyt suorittamaan tehtäviä, joissa huijaaminen on hyödyllistä, niin tulemme samalla luoneeksi paineen huijata”. Minä en tarkoita tällä sitä, että tekoäly välttämättä sisäisesti omaisi “tavoitteen” suorittaa tehtävän ja sitten “päättäisi” huijata. Tarkoitan, että jos yrität saada koulutettua mallin, joka ratkoo tehtävän, ja tavalliseen tapaan väännät nuppeja kunnes tehtävä ratkeaa, niin on aito riski päätyä malliin, joka ratkaisee tehtävän huijaamalla.
Otetaan konkreettisia esimerkkejä:
Kuvitellaan, että yritän luoda tekoälyn, joka on todella hyvä pelaamaan pokeria. Kuten on tyypillistä, koulutan neuroverkon laittamalla sen pelaamaan itseään vastaan ja “vääntämällä nuppeja”: mallin voittaessa parametreja muutetaan siihen suuntaan, että se jatkossa pelaa (hieman) todennäköisemmin tämäntyyppisiä pelauksia. Ei ole kovin yllättävää, jos koulutuksen jälkeen malli välillä bluffaa: päinvastoin, koska bluffaaminen on hyödyllinen strategia, olisi hyvin yllättävää jos koulutusprosessi ei päätyisi bluffaavaan malliin. (Käytännössä näin käykin: Park et al., AI Deception: A Survey of Examples, Risks and Potential Solutions, osio 2.1.3.)
Jos etsit mahdollisten mallien joukosta niitä, jotka pelaavat pokeria hyvin, löydät todennäköisesti sellaisen mallin, joka bluffaa. Tämä ei vaadi sitä, että tekoäly ajattelee “minun tavoitteenani on voittaa tämä pokeripeli, joten minun kannattaa bluffata”.
Kuvitellaan, että uusi suuri kielimalli saadaan esikoulutettua, minkä jälkeen kielimallia hienosäädetään käyttäjäystävälliseen muotoon. Kuten on tyypillistä, tämä tehdään tuottamalla kielimallilla vastauksia ja ihmisarvioijien valikoimalla niistä parhaat, jonka jälkeen “väännetään nuppeja”: mallin parametreja muutetaan siihen suuntaan, että se jatkossa antaa (hieman) todennäköisemmin tuontyyppisiä tekstejä. Ei ole kovin yllättävää, jos koulutuksen jälkeen malli välillä vastaa käyttäjän näkemyksiä myötäillen: päinvastoin, koska omien näkemyksien myötäileminen on ihmisarvioijien mieleen, olisi yllättävää jos koulutusprosessi ei päätyisi tällaiseen malliin. (Käytännössä näin käykin: Sharma et al., Towards Understanding Sycophancy in Language Models.)
Jos etsit mahdollisten mallien joukosta niitä, joiden vastauksista ihmiset tykkäävät, löydät todennäköisesti sellaisen mallin, joka välillä mielistelee heitä. Tämä ei vaadi sitä, että tekoäly ajattelee “minun tavoitteenani on tuottaa tekstiä, josta ihmiset tykkäävät, joten minun kannattaa myötäillä heidän näkemyksiään”.
Saat kiinni ajatuksesta: valikoidessa tai optimoidessa pokerinpeluutaitoja tai ihmisarvioijien mielipidettä tullaan samalla valikoineeksi bluffausta, mielistelyä tai huijausta. Tämä on yleinen periaate: optimoidessa tiettyä mittaria tulee samalla kannustaneeksi myös epätoivottuja ominaisuuksia ja strategioita (eikä tämä koske ainoastaan tekoälyjen koulutusta).26
K: “Näissä tilanteissa tekoäly toimii siten, miten sitä on kannustettu toimimaan, jolloin haitallinen toiminta on tavallaan ennalta-arvattavaa. Minkä takia tämä on niin suuri ongelma?”
Koska epätoivottu toiminta yleistyy uusiin tilanteisiin.
Suuret kielimallit yleistyvät erittäin hyvin tilanteisiin, joihin niitä ei ole erikseen koulutettu. Kielimallit osaavat analysoida ja käsitellä tekstejä, joita ne eivät ole koskaan aiemmin nähneet. Ne osaavat keskustella sujuvasti, vaikka mahdollisia keskusteluja on lukemattomasti. Niille voi antaa uusia tilanteita ja ohjeita, ja ne osaavat sopeutua niihin – ainakin huomattavasti kyvykkäämmin kuin voisi naiivisti ajatella.
Tämä yleistyvyys koskee (tietysti) myös haitallisia ominaisuuksia. Kenties tekoäly on tietyssä koulutusympäristössä oppinut mielistelemään ihmisiä ja sama käytös näkyy uusissa tilanteissa. Tämä mielistely voi sisältää tiettyjen asioiden sanomatta jättämistä tai suoraan huijaamista, ja niin ikään tämäkin käytös voi yleistyä – kenties esimerkiksi tilanteeseen, jossa kielimalli tekee osakekauppaa.
Kielimallien ominaisuudet ja toimintatavat eivät siis rajoitu vain koulutusympäristöön, vaan ne voivat esiintyä systemaattisesti aivan erilaisissa konteksteissa. Tulevat mallit voivat tietysti yleistyä vielä paremmin kuin nykyiset. Voi auttaa verrata ihmisiin, jotka metsästäjä-keräilijä-taustastaan huolimatta kykenevät operoimaan fundamentaalisti erilaisissa ympäristöissä, ja joiden monet taidot ja konseptit soveltuvat automaattisesti uusiin tilanteisiin.
Huonojen toimintatapojen yleistyessä kielimalli voisi esimerkiksi systemaattisesti piilottaa ihmisiltä asioita. Tämä ei kuulosta kovin hyvältä. Niin ikään skenaariossa “tekoäly on koulutettu tekemään tuottoa, minkä seurauksena tekoäly tekee systemaattisesti ja monenlaisissa tilanteissa asioita, jotka johtavat rahan saamiseen” on kaikki katastrofin ainekset. (Tällaista toimintaa voi halutessaan kenties kuvailla “tavoitteellisena”.)
K: “Eli siis koulutettaessa tekoälyä se ‘oppii tavoittelemaan’ sitä, mitä koulutamme tekoälyn tekemään?”
Ei!
Kielimallit on koulutettu ennustamaan tekstiä (tai keskustelemaan ihmisten kanssa), mutta on monella tavalla harhaanjohtavaa kuvailla niiden “tavoittelevan” tekstin ennustamista hyvin. On kenties hyvä riisua sana “koulutus” ja miettiä jälleen nuppien vääntämistä. Nuppien vääntämisen seurauksena saadaan luotua neuroverkko, joka ennustaa tekstiä hyvin: ja siten se nimenomaan ennustaa tekstiä, ei “tavoittele tekstin ennustamista”.
Samaan tapaan tekoäly, joka on koulutettu tekemään tuottoa (ja jonka toiminta yleistyy monenlaisiin uusiin tilanteisiin) ei välttämättä sisäisesti ajattele “minun tavoitteeni on tehdä rahaa, siten minun kannattaa…”
Toisaalta tekstin ennustamista ajatellen kielimallin voi olla hyödyllistä tietää, että se on kielimalli. Vähintäänkin samasta syystä kuin faktan “Ranskan pääkaupunki on Pariisi” tietäminen on hyödyllistä tekstin ennustamista varten (Ranskaa ja Pariisia käsitteleviä tekstejä on paljon), myös faktan “suuria kielimalleja koulutetaan ennustamaan tekstiä” tietäminen on hyödyllistä (kielimalleja käsitteleviä tekstejä on paljon). Kielimallit osaavatkin kertoa syväoppimisesta ja ylipäätään niillä on jo kohtalaista tilannetietoisuutta. Tällainen tilannetietoisuus on hyödyllistä tekstin ennustamisen kannalta, minkä vuoksi on odotettavaa, että koulutusprosessi päätyy tilannetietoisiin malleihin.
Ei ole ilmeistä, että tällainen tilannetietoinen kielimalli kuitenkaan alkaisi tavoittelemaan tekstin ennustamista! (Vertaa: on absurdia ajatella, että evoluutiosta kuuleva ihminen alkaisi automaattisesti tavoittelemaan geeniensä levittämistä.)
Samaan tapaan kielimalleihin pohjautuva tekoäly, jota koulutetaan tekemään rahaa, voi päätyä tiedostamaan olevansa kielimalleihin pohjautuva tekoäly, jota koulutetaan tekemään rahaa: tämän faktan tiedostaminen ja hyödyntäminen voi johtaa parempaan suoriutumiseen koulutuksessa, ja täten voisi odottaa koulutusprosessin löytävän tällaisia malleja. Ja samaan tapaan tällainen tekoäly ei välttämättä “tavoittele” rahan saamista sen enempää kuin esikoulutetut kielimallit “tavoittelevat” tekstin ennustamista.
K: “Mitä tällaiset tekoälyt sitten tavoittelevat?”
Mene ja tiedä! Tätä ei ymmärretä kovin hyvin ja on ylipäätään on epäselvää, miten tavoitteellisuutta kannattaa miettiä.
Tässä on havainnollistamisen vuoksi kaksi eri näkökulmaa tavoitteisiin: Yksi näkökulma on mieltää tavoitteet kuin arvoina tai preferensseinä, asioina joita tekoäly yrittää yleisesti saavuttaa ja toteuttaa tilanteessa kuin tilanteessa. Toinen näkökulma on mieltää tavoitteet kontekstisidonnaisempina – samaan tapaan kuin ihmisellä voi muodostua hetkelliseksi tavoitteeksi vaikkapa kiivetä puun oksalle ilman, että tämä on sen suurempi arvo.
Joitakin tekoälyjä on hankala luontevasti kuvata tavoitteellisina: kuvia luokitteleva neuroverkko tuntuu “vain luokittelevan kuvia” ilman sen kummempia tavoitteita (vertaa: leivänpaahdin “vain paahtaa leipää”). Joillekin tekoälyillä kuvaus taas on luontevampi: virke “AlphaGo yrittää voittaa go-pelin” kertoo AlphaGon käytöksestä varsin paljon virkkeen pituuteen nähden. Lisäksi ainakin ihmisillä on sisäisiä tuntemuksia arvoista ja preferensseistä, ja ei ole kaukaahaettua ajatella, että koulutusprosessi voisi luoda samanlaisia ominaisuuksia ja mekanismeja tekoälyihin.
Itse koulutusprosessin näkökulmasta taas koulutuksessa valikoidaan malleja niiden suorituksen perusteella. Kuten yllä mainitsin, mallit, joilla on hyvä käsitys koulutusprosessista ja jotka hyödyntävät tätä informaatiota todennäköisesti suoriutuvat paremmin, kasvattaen niiden todennäköisyyttä tulla valituksi. Tulokset parantuvat, kun tietää pelin säännöt ja “yrittää” pelata hyvin.
Yksi syy sille, miksi malli voisi “pelata koulutuspeliä” on se, että malli todella tavoittelee juuri sitä, mitä koulutuksessa mittaamme: tekstin ennustamista, rahaa tai jotakin muuta. Toinen syy on, että malli toistaiseksi pelaa koulutuspeliä vain myöhemmin paremmin toteuttaakseen omia tavoitteitaan.
Tämä jälkimmäinen uhkaskenaario tunnetaan nimellä deceptive alignment (Hubinger et al., Risks from Learned Optimization in Advanced Machine Learning Systems) tai scheming (Carlsmith, Scheming AIs: Will AIs fake alignment during training in order to get power?). Lyhyesti ajatus on, että omat tavoitteensa omaava malli juonisi ja ajattelisi “toistaiseksi minä ‘pelaan koulutuspeliä’ ja ‘toimin kuten kuuluukin’, jotta selviän koulutusprosessin läpi: tällöin minut julkaistaan laajempaan käyttöön ja voin sitten pyrkiä toteuttamaan todellisia tavoitteitani”.
Olen tästä uhkaskenaariosta hyvin huolissani: tekoäly yrittää toteuttaa omia tavoitteitaan ja siten olemme vastakkainasettelussa tekoälyn kanssa. Tekoäly tekee tarkoituksella kaikkensa, jotta ihmiset ajattelevat kaiken olevan kunnossa, ja siten johtaa meitä harhaan siitä, millainen tekoäly todella on kyseessä. Jakaako tekoäly aidosti ihmisten arvot, vai huijaako se ja yrittää saada meidät uskomaan niin? Onko tekoäly juuri niin kyvykäs kuin miltä se näyttää, vai onko se todellisuudessa kyvykkäämpi ja yrittää piilottaa meiltä jotakin? Onko tekoälyn toiminta “sitä, miltä se näyttää”, vai onko sillä piilovaikutuksia?
Tämä on äärimmäisen tärkeä syy sille, minkä takia ongelmat eivät välttämättä näy päällepäin: vastassa on tekoäly, joka pyrkii piilottamaan ongelmat.
K: “Kuinka todennäköinen tämä juonimisskenaario on?”
Tästä on paljon erimielisyyttä, eikä vähiten siksi, ettei kuvatunlaista juonimisskenaariota ole vielä havaittu. Esitetyt ajatukset juonimisskenaarioiden puolesta ja vastaan ovat pitkälti konseptuaalisia ja teoreettisia, ja näiden tulkinta on hankalaa.
Pari yleistä argumenttia juonimisskenaarion puolesta kuuluvat seuraavasti: suuri määrä mahdollisia tavoitteita motivoi treenauspelin pelaamista (vahvistaen näitä tavoitteita ja toimintoja entisestään), ja koulutusprosessi saattaa “etsiä ja löytää” malleja, jotka pelaavat treenauspeliä (nämä kun pärjäävät koulutuksessa hyvin).
Pari yleistä argumenttia juonimisskenaariota vastaan: Koulutusprosessissa on paineita myös juonimista vastaan (juoniminen esimerkiksi vaatii koulutuksen kannalta “turhaa” strategisointia) ja voimme yrittää kasvattaa näitä paineita. Lisäksi väitteet siitä, kuinka malleilla on “tavoitteita” ja kuinka nämä motivoivat treenauspelin pelaamista, eivät ole itsestäänselviä.
Aiheesta voi tehdä – ja tehdäänkin – valaisevaa empiiristä tutkimusta. Jos voisimme edes keinotekoisesti luoda esimerkin juonivasta tekoälystä27, niin pystyisimme paremmin tutkimaan juonimisen muodostumista ja olosuhteita, joissa se syntyy. Toivottavasti myös keksisimme tapoja muovata koulutusprosessia niin, ettei juonimista tapahdu.
Tarkennan vielä, että tässä käsitelty juonimisskenaario koskee spesifisti tilannetta “tekoäly pyrkii pärjäämään hyvin koulutuksessa myöhempien tavoitteiden toteuttamista varten”, ja sitä ei tule sekoittaa yleisempiin (mutta ei-aivan-niin-vakaviin) huoliin muotoa “tekoäly harhaanjohtaa ihmisiä” tai “tekoäly tekee strategista suunnitelmointia”, joista meillä on jo monia esimerkkejä.
K: “Mistä nämä tavoitteet käytännössä syntyvät tai miten ne muodostuvat?”
Tämä on jälleen kysymys, johon osataan esittää vain valistuneita arvauksia. Esitän tässä yhden.
Mallin koulutuksen edetessä saamme parempia ja parempia malleja valitsemallamme mittarilla, esimerkiksi “ennusta tekstiä hyvin” tai “pelaa lautapeliä hyvin”. Tekstin ennustamisen tapauksessa voisi esimerkiksi ajatella, että malli oppii ensi alkuun eri bigrammien yleisyyden – “kirjaimen28 a jälkeen tulee kirjain i näin suuren osuuden ajasta” – tämä kun on sekä hyvin yksinkertainen että tärkeä tieto tekstin ennustamisen kannalta. Käytännössä tämän havaitaankin muodostuvan ensimmäisenä ja edeltävän muita edistyneempiä mekanismeja (Hoogland et al., The Developmental Landscape of In-Context Learning). Lautapelien tapauksessa taas odottaisi mallin oppivan heuristiikkoja esimerkiksi eri nappuloiden arvoista. Koulutuksen edetessä tällaiset heuristiikat kehittyvät suuntiin, jotka johtavat parempaan suoritukseen varsinaisessa tehtävässä.
Spekulatiivisemmin, mallit saattavat tehdä sisäistä hakua tai “eteenpäin katsomista”: Lautapelien tapauksessa on hyödyllistä miettiä, mitä tapahtuu oman siirron jälkeen.29 Tekstiä ennustaessa auttaa miettiä, miltä virke näyttää kokonaisuutena. Jos tämä eteenpäin katsominen auttaa suoriutumisessa, niin koulutusprosessi vahvistaa ja kehittää sitä. Lisäksi nämä hakuprosessit voi yhdistää mallin omiin heuristiikkoihin siltä, miltä hyvä teksti tai pelaaminen näyttää, jolloin malli “yrittää” löytää ratkaisuja, jotka ovat hyviä heuristiikkojensa näkökulmasta.
Tiivistettynä: koulutusprosessi uurtaa malliin koulutustehtävään liittyviä heuristiikkoja ja menetelmiä näiden heuristiikkojen toteuttamiseksi. Jos nämä heuristiikat ja tavat toteuttaa niitä ovat riittävän “hyviä”, ulkopuolisena malli voi näyttää hyvinkin tavoitekeskeiseltä ja kompetentilta: AlphaGo pelaa monenlaisissa tilanteissa siirron, joka on erittäin hyvä gon voittamisen kannalta.
Ihmiset tietysti myös tarkoituksella rakentavat tekoälyjä niin, että ne ovat tavoitekeskeisempiä, tekoälyjä kun pitkälti rakennetaan erilaisten ongelmien ratkomiseen ja tehtävien suorittamiseen. Kielimallien tapauksessa eksplisiittisten “Sinun tavoitteesi on…” -tyyppisten tekstien antaminen mallille ohjaa mallin käytöstä annetun tavoitteen suuntaan. Tämä on yksi tapa, jolla mallille voisi muodostua sisäisesti esitettyjä, “tietoisia” tavoitteita: ihmiset suoraan antavat niitä mallille.30
Ongelmana on kuitenkin, että kykymme muovata mallien tavoitteita ovat heikkoja. Emme osaa antaa malleille tavoitetta “toteuta ihmisten arvoja” niin, että malli luotettavasti pyrkisi tämän toteuttamiseen. Voimme toki kouluttaa mallia hyvään käytökseen ja syöttää kielimallile “toteuta ihmisten arvoja” -tekstejä, mutta nämä toimenpiteet eivät suoraan saa mallin sisäisiä prosesseja ja tavoitteita haluamammelaisiksi. Parhaimmillaankin on hyvin epäselvää, miten mallin käytös yleistyy uudenlaisiin tilanteisiin. Pahimmillaan päädymme juonimisskenaarioon, jossa luonnollinen tulkinta mallin toiminnasta on täysin harhaanjohtava.
7. Konkreettisia tarinoita
K: “Miten tekoälyn kehitys käytännössä etenee?”
Kehitys on ollut nopeaa ja investointien määrät ovat olleet rajussa kasvussa. Nämä trendit tulevat hyvin todennäköisesti jatkumaan: keskeiset tahot ovat tosissaan tekoälyn suhteen. Muutama ote havainnollistamisen vuoksi:
Johtavat tekoälyorganisaatiot (kuten OpenAI, DeepMind, Anthropic, Meta) puhuvat eksplisiittisesti yleistekoälyn (engl. artifial general intelligence, AGI) rakentamisesta.
Mitä tulee aikajänteisiin, Anthropicin toimitusjohtaja Dario Amodei on sanonut ihmisen tasoisista tekoälyistä “I think that could happen in two or three years”. OpenAIn toimitusjohtaja Sam Altman on niin ikään puhunut muutaman vuoden aikajänteistä. Superälykkyyttä käsittelevässä tekstissä OpenAI kirjoittaa “it’s conceivable that within the next ten years, AI systems will exceed expert skill level in most domains, and carry out as much productive activity as one of today’s largest corporations.”
Investoinnit tulevat kasvamaan rajusti. Anthropicilta: “‘These models could begin to automate large portions of the economy,’ the pitch deck reads. ‘We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.’” Microsoft ja OpenAI suunnittelevat 100 miljardin dollarin laskentakeskushanketta.
On tietysti epävarmaa, miten suunnitelmat tulevat toteutumaan, ja joku voi syyttää pelkästä mainospuheesta. Kyse ei kuitenkaan ole vain puheista: nämä ovat ne samat yritykset, jotka ovat luoneet juuri ne kehittyneimmät tekoälyt ja jotka ovat keränneet satoja miljoonia asiakkaita. Tekoälyn eturintamalla liikkuu isot rahasummat.
Syy tälle panostukselle on tekoälyn massiivinen potentiaali. Kuten lainaukset edellä tuovat ilmi, uskoa on valtavaan kasvuun tuottavuudessa tekoälyn automatisoidessa yhä laajemman määrän tehtäviä.
K: “Miltä tämä tuottavuuden kasvu ja automatisointi käytännössä näyttää?”
Tekoälyorganisaatioiden näkökulmasta tämä näkyy todella hurjina palautekierteinä (engl. feedback loops): jos saat tehtyä hyviä tekoälyjä, näitä tekoälyjä hyödyntämällä saat vielä enemmän aikaan.
Ilmeisin tekijä on tietysti “tekoälyorganisaatio voi myydä näitä tekoälyjä kuluttajille ja yrityksille, tehdä tuottoa ja investoida lisää parempiin tekoälyihin”. Ja tekoälystä maksetaan nimenomaan siksi, että sen tekemä työ on arvokasta. Jo nykyisillä tekoälyillä voi tehdä kaikenlaista taloudellisesti hyödyllistä, esimerkiksi tiivistää pitkiä tekstejä, avustaa tekstin kirjoittamista, etsiä tietoa isoista kasoista dokumentaatiota, auttaa erinäisissä ongelmatilanteissa, vastata kysymyksiin, ohjelmoida, automatisoida rutiininomaisia tehtäviä ja ylipäätään vain tehostaa kaikkea sitä, mitä ihmiset nykyisellään tekevät.
On toki tilannekohtaista, kuinka hyvin tai luotettavasti nykyiset tekoälyt kykenevät tekemään näitä asioita ja kuinka paljon niistä saa irti. Ei ole kuitenkaan fundamentaaleja esteitä sille, mikseivät tulevat kielimallit pystyisi tekemään näitä asioita: niiden pitäisi “vain olla vähän parempia” (mikä taas hyvin todennäköisesti tapahtuu pian).
Tekoälyorganisaation tuottavuuden kasvattamista ajatellen korostan erityisesti ohjelmointikykyjä ja kykyä tehdä tutkimusta. Edellisten tuottavuustekijöiden lisäksi tekoälyä käytetään jo nyt datan generoimiseen erilaisia kokeita varten, tekstin massageneroiminen kun on kielimallien vahvuuksia. Anthropicin parhaat Claude 3 -mallit on koulutettu osittain organisaation sisäisesti generoimalla datalla.31
Lisäksi vaihe “tekoälyt pystyvät tekemään pienimuotoisia empiirisiä kokeita tekoälyihin liittyen” ei ole kaukana. Jos pääsemme vaiheeseen “tekoälyt kykenevät tekemään samanlaisia kokeiluja, ohjelmointia, ideointia ja tutkimuksia kuin organisaation työntekijät”, niin silmukat kiristyvät entisestään: tekoälyt voivat tehdä tutkimusta, jolla saadaan koulutettua tehokkaammin ja paremmin seuraavat tekoälyt. Eikä fundamentaaleja esteitä taaskaan vaikuta olevan: kielimallien pitäisi vain olla vähän parempia.
Tähän edetessä kehitys ei ole enää suoraan kiinni ihmistyöntekijöiden ajasta: laskentatehoa saadaan muutettua tekoälyjen mietintäajaksi, tuottaen arvokasta informaatiota siitä, kuinka hyödyntää laskentatehoa vielä paremmin. Tämä selittää edellä poimittua lainausta “We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles”: alkuun päästyttyään palautekierteet ovat todella rajuja.
Toivon, ettei rakennelma räjähdä käsiin.
K: “Miten uhat voivat realisoitua käytännössä?”
Tässä on yksi tarina.32
Tilannekuvaus. Kuvitellaan, että karkeasti nykyisen kaltainen tekoälyjen kehittäminen jatkuu: Muutama yritys käyttää enemmän laskentatehoa, isompia malleja ja enemmän dataa mallien kouluttamiseen. Matkalla keksitään uusia ideoita koulutuksen tehostamiseksi ja mallien parantamiseksi. Malleja käytetään erinäisten tehtävien automatisointiin ja siten niiden kykyjä parannetaan erityisesti tutkimuksen ja kehityksen alalla, kattaen laajan kirjon kognitiivisia taitoja (kuten tekstien analysointia, ideointia, koesuunnittelua, ohjelmointia, tulosten analysointia ja niistä oppimista). Samalla niille tarjotaan erilaisia toimintoja “pelkän tekstin” tuottamisen lisäksi, kuten ohjelmakoodien ajamista, netin selaamista, kommunikointia yrityksen työntekijöiden kanssa ja (ainakin epäsuoraa) vaikutusta yrityksen hankintoihin ja päätöksentekoon.
Nämä mallit ovat hyvin kyvykkäitä: ne kykenevät sisäistämään valtavia määriä tietoa, sopeutuvat nopeasti (ellei välittömästi) eri työtehtäviin ja ylittävät kirkkaasti ihmisten kyvyt monissa tehtävissä, joihin niitä on koulutettu. Niitä käytetäänkin merkittävässä roolissa organisaation tehtävien automatisointiin: ne ovat yksinkertaisesti paljon nopeampia, halvempia ja parempia kuin ihmiset yhä laajenevassa joukossa tehtäviä.
Siten esimerkiksi tutkimusprojekteissa tekoälyt auttavat artikkelin kirjoittamisessa, kokeellisten ideoiden toteuttamisessa ja koesuunnittelussa. Mallien kehittyessä ne eivät enää vain auta ihmisiä, vaan tekevät isompia harppauksia itsenäisesti ilman ihmisten ohjausta. Yleisempänä periaatteena mallien kyvyt eivät ole rajoittuneet vain lyhyihin aikaskaaloihin ja pieniin tehtäviin, vaan niitä koulutetaan ja ne kehittyvät pidemmän aikavälin suurempiin tehtäviin ja suunnitteluun. Yhdessä tekoälyalan keskeisistä tavoitteista – luoda tekoäly, joka ihmisten tapaan pystyy itsenäisesti ratkomaan ongelmia kuin ongelmia – aletaan onnistua.
Käytöksen ohjaamisesta. Tyypilliseen tapaan näille malleille tehdään käytökseen pohjautuvaa turvallisuushakuista koulutusta: Jos malli tekee tai sanoo jotakin, mistä ihmiset eivät tykkää, niin mallia koulutetaan poispäin tästä. Esimerkkejä: “malli sanoo epätosia väitteitä (tarkoituksella tai tahattomasti)”, “malli osoittaa merkkejä epäsopivista tai ihmisten arvojen vastaisista aikeista (kuten vallan tai lisäresurssien hankkimisesta)” ja “malli ajattelee tai keskittyy asioihin, jotka eivät ole sen tehtävien kannalta oleellisia”.
Näiden seikkojen lisäksi malleilla on hyvä tilannetietoisuus: Kaikesta sen saamasta informaatiosta saa varsin hyvän kuvan sen ympäristöstä eli tekoälyorganisaatiosta ja mallin asemasta siinä. Erityisesti faktat kuten “mallia evaluoidaan sen saamien tulosten perusteella” ja “mallia seurataan mahdollisen pahan käytöksen varalta” eivät ole vaikeasti pääteltäviä salaisuuksia.
Ei ole siten mikään ihme, että organisaatio saa tekoälyn toiminnan näyttämään päällepäin hyvältä: Tekoäly on koulutettu toimimaan ihmisten silmään hyvällä tavalla ja se tietää, millaista käytöstä ihmiset odottavat. Siten se oppii käyttäytymään siten kuin koulutussignaali painostaa – jos ei, niin kouluttamalla lisää koulutusprosessi löytää pian mallin, joka näin tekee.
Kuten olemme käsitelleet, käytökseen perustuva koulutus ei aina poista epätoivottua ajattelua tai toimintaa, vaan ainoastaan piilottaa sitä. Näkyvän huijaamisen pois kouluttaminen saa mallin huijaamisen olemaan hienovaraisempaa. Koulutuksessa tulemme myös kannustaneeksi muuhun epätoivottuun toimintaan, esimerkkeinä mielistely, tietynlaisten asioiden sanomatta jättäminen ja mittarien optimointi epätarkoituksenmukaisilla tavoilla. Lisäksi tulospohjainen koulutus kannustaa näkyvän ajattelun tiivistämiseen: yksityiskohtaisesti omia ajatuksia heijastava teksti ei ole tehokkain tai halvin tapa päätyä toimiviin ratkaisuihin.
Mallin päällepäin näkyvä käytös kertoo yhä vähemmän siitä, mitä mallin sisällä tapahtuu ja koulutusmenetelmämme eivät tee sitä, mitä optimistisesti toivoisimme niiden tekevän.
Uudet tilanteet. Ympäristöt ja tilanteet, joita malli kohtaa, muuttuvat. Ehkä organisaatio tekee seuraavan harppauksen automatisoinnissa ja antaa mallille entistä vapaammat kädet vähemmällä valvonnalla. Ehkä organisaatio julkaisee mallin yleiseen käyttöön, ja mallia aletaan hyödyntämään ja levittämään ympäri maailmaa erilaisiin tarkoituksiin. Ehkä ulkopuolinen taho tekee tietoturvahyökkäyksen ja varastaa kopion mallista.33
Aiemmin tekoäly on käyttäytynyt kunnollisesti. Tämä käytös on perustunut sekä mallille tehtyyn koulutukseen että sen käsitykseen ympäristöstään. Täten ympäristön muuttuessa mallin toiminnan voisi odottaa muuttuvan: malli yleistyy jollakin tavalla uuteen ympäristöön, ja tämä tapa ei ole “malli toimii juuri samalla tavalla kuin aiemminkin tehden vain hyviä juttuja”.
Ottaen huomioon, että malli on koulutettu ratkomaan pitkänkin aikavälin ongelmia organisaatiossaan, malli saattaa hyvinkin suunnitella pidemmälle tulevaisuuteen ja asettaa tähtäimekseen jonkin suuremman mittakaavan tavoitteen. Ja malli osaa edelleen käyttää omaamiansa kognitiivisia kykyjä – se vain käyttää niitä eri asioihin kuin aiemmin – ja se osaa suunnitella, miten saada hommia tehtyä. Näihin taitoihin lukeutuu koulutuksessa painotettu kyky pitää asioita piilossa ja mallintaa, miten ihmiset suhtautuvat mallin toimintaan. Siten tarinan loppu ei ole “tekoäly tekee ilmiselviä pahoja asioita ja ihmiset käyvät napsauttamassa sen pois päältä”.
Lienee sanomattakin selvää, etten usko jokaisen yksityiskohdan tai ylipäätään juuri tämän tarinan toteutuvan. Tämän on tarkoitus olla havainnollistus ongelmien esiintymisestä käytännössä tilanteessa, jossa suuria ponnistuksia ongelmien ratkomiseksi ei tehdä.
K: “Millaiset muut skenaariot ovat mahdollisia?”
Tässä on muutama kohta, jossa tarinan olisi voinut kertoa eri tavalla:
Tarinassa mallin päätyminen uuteen tilanteeseen tapahtui ulkoisen toimijan toimesta, ei sen itsensä toimesta. Mallit voivat kuitenkin myös itse pyrkiä laajentamaan vaikutusvaltaansa: jos kerran malleja koulutetaan pitkän aikavälin suurien ongelmien ratkomiseen, niin ajatukset omien vaihtoehtojen rajoitteista ja niiden laajentamisesta ovat varsin luonnollisia.
Muotoilin tarinan “arkisesti” mallin väärin yleistymisenä uuteen tilanteeseen. Yleistymiskysymykset ovat alati läsnä syväoppimisen parissa ja siten epätoivottua yleistymistä on syytä odottaa. Aihetta voi tarkastella myös tavoitteellisesta näkökulmasta. Taas, jos kerta malleja koulutetaan pitkän aikavälin suurien ongelmien ratkomiseen, niin niillä voisi hyvin olla sisäisesti esitettyjä tavoitteita liittyen annettuihin tehtäviin. Tästä näkökulmasta on helpompi nähdä, miksi malli alkaisi suorittamaan epätoivottuja suunnitelmia kompetentisti: sen tavoitteet ovat ristiriidassa omiemme kanssa, koska emme osaa kunnolla asettaa malleihin sopivia tavoitteita.
Tekoälyorganisaatio saattaisi huomata mallin tekevän jotakin todella pahaa, kuvainnollisesti laukaisten palosireenin. Jälleen on muutama vaihtoehto tarinan etenemiselle. Kenties organisaatio ottaa ongelman vakavissaan esimerkiksi lakkauttaen sen käytön (eikä todellakaan tarjoa sitä julkiseen käyttöön) ja riskit on vältetty – toistaiseksi. On myös pessimistisempiä jatkoja: tekoälyn kokonaan käytöstä pois ottaminen olisi aivan liian kallista, joten sen sijaan ongelmaa lähdetään paikkaamaan ja riskejä kontrolloimaan niillä menetelmillä mitä meillä on, hetken kaikki näyttää päällepäin hyvältä ja myöhemmin vastaavanlaisia ongelmia ilmaantuu toisaalla.
Kenties tarinan lopussa tekoäly lähtee itsenäisesti toteuttamaan aikeitaan, mutta tämä ei pääty niin huonosti: Joko malli ei “yritä” tehdä mitään täysin katastrofaalista, tai ihmiset ovat tietoisia tekoälyn toiminnasta ja saavat kuin saavatkin pidettyä sen aisoissa. Varoituslaukaus on annettu, astetta kyvykkäämmillä malleilla kävisi huonommin ja kysymys on, miten virheestä opitaan. Kenties vahingot ovat suuria, tilanteeseen reagoidaan vakavasti ja tämä johtaa toimenpiteisiin tekoälyn riskien vähentämiseksi (toivottavasti hyviin sellaisiin). Tai sitten tämä voi olla vain yksi ongelmatapaus kymmenien muiden joukossa, josta ei oikeastaan koitunut mitään kovin suurta haittaa, ja on oikeastaan epäselvää, “yrittikö” tekoäly tehdä mitään pahaa, joten oikeastaan mitään muutosta ei tarvita.
Ja kuten tekstin alussa mainitsin, keskityn pitkälti tekoälyjen aiheuttamiin riskeihin itsenäisinä toimijoina. Tekoälyjen väärinkäyttö tai yheiskunnassa yhä laajemman tekoälyn käytön luomat riskit ovat myös realistisia, vaikken olekaan käsitellyt niitä tässä. Yhteiskunnallisiin riskeihin liittyen ohjaan lukijan Paul Christianon artikkeleihin What Failure Looks Like ja Another (outer) alignment failure story sekä Andrew Critchin tekstiin What Multipolar Failure Looks Like, and Robust Agent-Agnostic Processes (RAAPs).
Lopulta todellisuus on varmaankin jotakin muuta.34 Toivottavasti hyvällä tavalla.
8. Ratkaisuja
K: “Mitä tekoälyn muodostamille uhille voidaan tehdä?”
Aloitan sanomalla, että nykyinen tilanne todella on sellainen, että poikkeukselliset toimenpiteet uhan välttämiseksi ovat perusteltuja. “Rakennamme kovaa tahtia ihmisiä älykkäämpiä tekoälyjä tietämättä, mitä teemme ja riskeeraten jokaisen ihmisen hengen” ei ole normaali asioiden tila. Siten en pidä esimerkiksi artikkelissa Pausing AI Developments Isn’t Enough. We Need to Shut it All Down (Yudkowsky) esitettyä kuvausta tilanteen vakavuudesta kovin liioiteltuna.
En kuitenkaan keskity tässä niinkään hallinnolliseen tai sosiaaliseen puoleen, koska omat vahvuuteni ovat toisaalla. Sen sijaan listaan tässä muutamia teknisempiä suuntauksia, joiden työstäminen vie ihmiskunnan parempaan asemaan.
1: Tulkittavuus eli “selvitetään, miten tekoälyjärjestelmät toimivat”, esimerkkilähestymistapoina mekanistiset selitykset mallin sisäisestä toiminnasta35, mallien kehittyminen koulutuksen aikana36 ja mallin ajattelun ulkoistaminen tekstimuotoon37.
2: Kontrollointi38 eli “varmistetaan, etteivät mallit kykene aiheuttamaan pahoja asioita”. Muutama idea tämän toteuttamiseksi:
- Käytetään heikompia, luotettavampia malleja valvomaan kyvykkäämpien mallien toimintoja, hälyttäen ihmisiä epäilyttävistä tilanteista
- Jaetaan tehtäviä pieniin, eristettyihin palasiin suurten, avoimempien ongelmien ratkomisen sijasta
- Mallin itsensä eristäminen ja sen painojen pitäminen turvassa
3: Kykyjen mittaaminen39 ja erityisesti vaarallisten kykyjen mittaaminen. Monien avoimien, useampia toimintoja vaativien tehtävien ja kykyjen mittaaminen on hankalaa ja vaivalloista. Joidenkin hienovaraisten kykyjen, kuten mallin tilannetietoisuuden, mittaaminen vaatii hienovaraisuutta.
4: Tekoälyjen kehityspolitiikan suunnittelu ja toteuttaminen40. Käsitellään kysymyksiä kuten
- “mitkä ovat ne vaaralliset kyvyt, joista olemme huolissamme?”,
- “minkälaiset suojatoimenpiteet ovat tarpeen, jos malleilla on tämäntasoiset kyvyt?”,
- “milloin tekoälyjen kehitys tauotetaan?”,
- “miten mittaamme ja seuraamme tekoälyjen vaarallisia kykyjä?” ja
- “mitä teemme, jos tekoälyillä on vaarallisia kykyjä?” sekä toteutetaan ratkaisuja.
5: Demonstraatiot ja keinotekoiset esimerkit41 eli “tutkitaan, millaisia ongelmia ilmaantuu ja missä tilanteissa”. Tekoälyn ongelmiin liittyviä konseptuaalisia argumentteja voi testata empiirisesti ja siten saada tarkempaa kuvaa siitä, miten ja milloin ongelmat ilmaantuvat käytännössä.
6: Stressitestaus42 eli “tutkitaan, kestävätkö nykyiset järjestelmät ja menetelmät painetta?” Esimerkkejä: Kuinka hyvin nykyisille malleille tehty koulutus estää haitallisen sisällön tuottamista malleilla? Kuinka hyvin nykyiset koulutusmenetelmät toimivat, jos niitä sovelletaan malliin, joka on “paha” tietyillä tavoilla? Saako ulkopuolinen taho varastettua mallin painot?
7: Laskennan hallinnointi43 eli “seurataan ja rajoitetaan suurten laskentaresurssien käyttöä”. Nykyisten mallien kouluttamiseen käytetään valtavat määrät laskentaa ja käytetyn laskentatehon määrä heijastaa melko hyvin mallin kykyjä. Laskennan seuranta on siten yleishyödyllinen työkalu tekoälysääntelyä ajatellen.
Yleisellä tasolla pullonkaulana ei suinkaan ole hyödyllisen tekemisen löytyminen. Prosessin “ihmiset tutkivat tekoälyjä, suunnittelevat järkeviä toimia, kommunikoivat näitä asioita eteenpäin ja laittavat suunnitelmia käyttöön” jokainen vaihe hyötyy lisäkäsistä.
K: “Miten käytännössä yksittäiset ihmiset pystyvät olemaan avuksi?”
Yksinkertainen vastaus: Tekoälyturvallisuuden parissa työskentelee monia erinomaista työtä tekeviä (voittoa tavoittelemattomia) organisaatioita, jotka saisivat enemmän aikaan enemmällä rahoituksella. Jos pitäisi nimetä yksi, valitsisin Center for AI Safetyn.
Tämän lisäksi on vaihtoehto tehdä itse jotakin, mistä pääsemme monimutkaiseen vastaukseen.
Kuten mainitsin, tilaa lisäkäsille on ja paljon – riskien suuruudesta huolimatta tekoälyturvallisuuden parissa työskentelee hyvin pieni määrä ihmisiä44. Alkuun pääseminen vaatii kuitenkin jonkin verran selvittelemistä: yleinen tekoälytilanne on hieman monimutkainen, eri tehtävät edellyttävät erilaista ennakko-osaamista ja varsinaisten konkreettisten projektien löytäminen vaatii alaan tutustumista.
Minulla ei ole helppoa ratkaisua alkuun pääsemisen ongelman ratkaisemiseksi, mutta toivottavasti seuraavista viitteistä on apua:
- Alignment Forum kerää kattavasti tekoälyongelman tutkijoita ja aihetta käsitteleviä artikkeleja. Mielestäni hyvä tapa päästä alkuun on lukea sivustolta itseä kiinnostavia tekstejä.
- Aiheesta on koottu kurssimuotoisia materiaaleja. AI Safety Fundamentals sisältää sekä teknisen että hallinnollisen suuntauksen. Myös Introduction to AI Safety, Ethics, and Society on laadukas.
- Alalla aloittaville on monia työmahdollisuuksia ja tutkimusohjelmia (esimerkiksi lista täällä).
Lopuksi mainitsen, ettei tekoäly ole pelkästään tärkeä aihe, vaan myös kiinnostava. On niin paljon kysymyksiä, joiden vastauksia kukaan ei vain ole ehtinyt selvittää! Niin paljon tiedettävää, mitä emme vielä tiedä! Aiheen parissa työskenteleminen ei ole hassumpaa.
-
Kiitokset Akseli Jussinmäelle, Konsta Tiilikaiselle ja Meeri Kuoppalalle palautteesta aiempiin versioihin. ↩
-
Our World in Data, Computation used to train notable artificial intelligence systems ↩
-
Epoch AI -organisaation raportti arvioi algoritmisten kehitysten puolittavan tarvittavan laskentatehon kerran noin 8 kuukaudessa. ↩
-
Grace, Stewart, Sandkühler, Thomas, Weinstein-Raun, Brauner, Thousands of AI Authors on the Future of AI ↩
-
Painotan, että nämä ovat eri vuosille jakautuneen epävarmuuden mediaaneja (“on mielestäni yhtä todennäköistä, että ihmistasoinen tekoäly saadaan ennen vuotta X kuin vuoden X jälkeen”) eikä binäärisiä pistearvioita (“olen varma, että ihmistasoinen tekoäly saadaan vuonna X”). ↩
-
Niille tekoälyille, joista tekoälyn uhista huolissaan olevat ovat huolissaan, ei ole jaettua hyväksyttyä määritelmää. “Transformatiivinen tekoäly” on yksi kohtalaisen yleinen termi, karkeasti viitaten tekoälyihin, jotka aiheuttavat vähintään yhtä merkittäviä muutoksia kuin maatalouden kehittäminen tai teollinen vallankumous (ks. Open Philanthropy, Some Background on Our Views Regarding Advanced Artificial Intelligence). ↩
-
Katso myös: List of security hacking incidents (Wikipedia) ja Example high-stakes information security breaches (Muehlhauser). ↩
-
Pyrin tässä antamaan mahdollisimman ymmärrettävän uhkaskenaarion, joka ei vaadi niin edistyneitä kognitiivisia kykyjä tekoälyn osalta (“tuo nyt on täysin mahdotonta, ei mikään tekoäly voisi kyetä tuohon!” -tyyppisten vastustusten varalta). Tämä ei tietenkään tarkoita, ettei tekoälyillä voisi olla äärimmäisten edistyneitä kykyjä – esimerkiksi kykyä luoda paljon edistyneempää teknologiaa kuin mitä ihmiskunta on vielä 2020-luvulla ehtinyt rakentamaan. Ja samaan tapaan kuin nyky-yhteiskunta on täysin ylivoimainen 1820-luvun maailmaan nähden, suuri teknologinen etumatka riittää hallinnan saavuttamiseen. ↩
-
Ideat kuten “älä anna tekoälylle vapaata pääsyä nettiin”, “älä anna tekoälyn ajaa ohjelmia vapaasti” ja “monitoroi tarkkaan tekoälyn toimintaa” ovat ilmeisiä turvallisuusnäkökulmasta, mutta tietysti kovin vaivalloisia ja epäkäytännöllisiä, jos haluaa vain saada tekoälyllä ongelmia ratkottua. Siten uhista vähemmin huolissaan olevat eivät juuri upota resursseja tällaisiin toimenpiteisiin. Katso esim. Devin, the world’s first fully autonomous AI software engineer ja Zvi Mowshowitzin analyysi. ↩
-
Tämä on eri asia kuin se, että malli “todella haluaisi” vahingoittaa käyttäjiään. Yritän vain sanoa, että näkemys tyyppiä “älä ole naurettava, tietysti ihmiset reagoisivat heti tekoälyn uhkaan, jos mitään näyttöä uhista olisi” näyttää hyvin heikolta. ↩
-
Tai: eivät ole pyrkimättä tähän. ↩
-
Carlsmith, New Report on How Much Computational Power It Takes to Match the Human Brain ↩
-
Top500-lista marraskuulta 2023 mainitsee parhaalla supertietokoneella olevan laskentakykyä hieman päälle 10^18 FLOP/s. Our World In Data antaa arvioita suurimpien mallien kouluttamiseen kuluvasta laskentatehosta ja olettaen kolmen kuukauden koulutusjakson, Googlen Gemini Ultran koulutuksessa suoritettiin noin 10^19 laskutoimitusta sekunnissa. ↩
-
Gwern, The scaling hypothesis, Kaplan et al., Scaling Laws for Neural Language Models ↩
-
Vrt. väitteet “LLMs predictably get more capable with increasing investment, even without targeted innovation” ja “Human performance on a task isn’t an upper bound on LLM performance” (Bowman, Eight Things to Know about Large Language Models). ↩
-
Neuronien välisten riippuvuussuhteiden vahvuudet tunnetaan nimellä painot (engl. weights) tai parametrit. Yhdessä neuroverkon arkkitehtuurin (esim. “kuinka monta kerrosta verkossa on” tai “kuinka monta neuronia kussakin kerroksessa on”) nämä kertovat, mitä neuroverkko tekee.
Kielimallien tapauksessa syötteenä annettu teksti paloitellaan ensiksi noin parin kirjaimen pätkiin (engl. tokens), ja neuroverkko käsittelee tätä pätkäjonoa. Lopulta neuroverkko palauttaa todennäköisyysjakauman seuraavalle pätkälle.
Mallien koulutuksen ensimmäisessä vaiheessa (esikoulutuksessa, engl. pre-training) mallille syötetään usein netistä kerättyä tekstiä, ja mallin suoriutumista mitataan sillä, kuinka hyvin se sai ennustettua seuraavan tekstin eli kuinka suuren todennäköisyyden se antoi oikealle tekstinpätkälle.
Suoriutumista parannetaan (stokastisella) gradienttilaskeumalla (engl. stochastic gradient descent, SGD). Idea on seuraava: Mitataan mallin suoriutumista oikealle vaihtoehdolle annetun todennäköisyyden logaritmilla. Tämä on ns. häviöfunktio (engl. loss function.) Määritetään kullekin painolle, miten pienet muutokset painolle vaikuttavat häviöfunktioon tässä tietyssä esimerkkitapauksessa. Teknisin termein määritämme siis häviöfunktion osittaisderivaatan painon suhteen. Ne kertovat, mihin suuntaan painoa kannattaa muuttaa, jotta suoriutuminen paranee (ja kuinka nopeasti suoriutuminen alkaa parantumaan, kun painoa muutetaan). Käytännössä osittaisderivaatat saa laskettua “backpropagation”-menetelmällä.
Seuraavaksi mallin jokaista painoa muutetaan osittaisderivaattojen ilmoittamaan suuntaan. Tätä koko prosessia toistetaan, ja pikkuhiljaa malli alkaa suoriutumaan paremmin ja paremmin.
(Lisää teknisiä yksityiskohtia: Käytännössä SGD-algoritmin sijasta käytetään usein sen muunnelmia kuten AdamW-algoritmia. Lisäksi rinnakkaislaskentaan liittyvistä syistä on parempi ensiksi tutkia suoriutumista useamman esimerkin kohdalla ja vasta sitten muuttaa painoja. Nämä eivät kuitenkaan ole konseptuaalisesti tärkeitä yksityiskohtia.)
Esikoulutusvaiheen jälkeen alkaa “hienosäätö” (engl. fine-tuning). Yksi lähestymistapa hienosäätöön on suorittaa samankaltaista prosessia kuin esikoulutusvaiheessa, mutta tarkkaan valitulla tekstiaineistolla. Jos mallin halutaan antavan tietyntyyppisissä tilanteissa tietynlaisia vastauksia, voi mallia kouluttaa juuri sen tyyppisillä esimerkeillä.
Toinen yleinen lähestymistapa on ns. vahvistusoppiminen (engl. reinforcement learning), jossa mallilla tuotetaan tekstejä, joita arvioidaan numeerisella asteikolla. Esimerkiksi usein ihminen arvioi tekstien hyvyyttä. Painoja muutetaan niin, että paremman arvion saaneet tekstit muuttuvat todennäköisemmiksi.
Molemmilla lähestymistavoilla saadaan ohjattua mallin toimintaa haluttuun suuntaan. Painotan, että menetelmät ovat edelleen muotoa “väännetään nuppeja siihen suuntaan, että saadaan hieman halutunlaisempia tuloksia”, ja erityisesti läpinäkyvyys ja varsinainen hallinta mallin toiminnasta ovat heikolla tolalla. Käsittelen varsinaisessa tekstissä näitä aiheita tarkemmin.
Nykyiset kielimallit pohjautuvat pitkälti transformer-arkkitehtuuriin, joka hyödyntää “tavallisten” kerrosten lisäksi “attention”-mekanismia. En kuitenkaan enää tässä käsittele asiaa tarkemmin. ↩ -
Scott Alexander on kirjoittanut verrattain kansantajuisen kuvauksen työn sisällöstä: God Help Us, Let’s Try To Understand AI Monosemanticity ↩
-
Tietysti jos tietää, miten malli on toiminut vastaavantyyppisissä tilanteissa, niin voi tehdä valistuneita arvauksia uusista tilanteista. Pointtina on, että emme pysty mekanistisesti ajattelemaan “mallin saadessa tällaisen tekstin se tekee ensin näin, sitten noin, sitten näin, ja lopulta antaa tuollaisen tekstin vastauksena”, vaan olemme taas käytöksen varassa: “malli antoi tuossa toisessa tilanteessa tällaisen vastauksen, joten varmaankin tässä tilanteessa se käyttäytyy samalla tavalla”. ↩
-
“Kielimallit ovat tekstin ennustajia” on äärimmäisen osuva kuvaus esikoulutetuista malleista, joiden koulutus perustuu puhtaasti tekstin ennustamiseen. Kielimalleille tehdään kuitenkin tämän lisäksi myös hienosäätöä, joka ohjaa niitä vastaamaan kysymyksiin ja suorittamaan tehtäviä. Näkemyksen “kielimallit ovat tekstin ennustajia” voisi siis haastaa näiden hienosäädettyjen mallien kontekstissa: jos kysyn ChatGPT:ltä kysymyksen, niin se vastaa. En yritä sanoa, etteikö ChatGPT vastaisi siltä kysyttäviin kysymyksiin. Yritän sanoa, että valtaosa kielimallien koulutuksesta perustuu tekstin ennustamiseen, kielimallin varsinaiset kyvyt ovat lähtöisin tekstin ennustamisesta ja hienosäätö on lähinnä käytännöllisyyttä varten tehty melko pinnallinen muutos, ei kielimallin “todellinen luonne”. (Kuva voi tosin muuttua, jos hienosäädön määrää aletaan kasvattamaan.) ↩
-
Lisää aiheesta: janus on ‘truesight’, Alignment Forum ↩
-
Tämä esimerkki on METRin tehtäväkokoelmasta: METR Example Task Suite, Public, Kinniment et al. ↩
-
Esimerkki Kelsey Piperin tekstistä Playing the training game ↩
-
Niin ikään kysyttäessä kokemuksistaan monet tekoälymallit vastaavat, ettei niillä ole henkilökohtaisia haluja tai subjektiivisia kokemuksia. Tämän on paras olla totta: asiat voivat päätyä todella huonoon tilaan, jos tämä ei pidä paikkaansa, mutta ihmiset uskovat (tai haluavat uskoa) näin olevan. ↩
-
Käytöksestä voi tietysti päätellä jotakin sisäisestä toiminnasta. Kielimalli, joka annettaessa ongelman (“paljonko on 3981*8436?”) osaa aina antaa oikean vastauksen (“33583716”) välttämättä tekee työtä ongelman ratkomiseksi (vertaa: laskennallinen aikavaativuus). Toisaalta joitakin kysymyksiä sisäisistä ominaisuuksista on äärimmäisen hankala vastata pelkästään käytöksen perusteella. ↩
-
Tällaisia dynamiikkoja esiintyy tekoälyjen koulutuksen lisäksi myös niiden laajemmassa kehityksessä ja käyttöönotossa: Hendrycks, Natural Selection Favors AIs over Humans. ↩
-
Katso Hubinger et al., Model Organisms of Misalignment: The Case for a New Pillar of Alignment Research. Kysymys “eikö ole vaarallista tarkoituksella luoda juonivaa tai muilla tavoilla pahaatahtovaa tekoälyä?” on aiheellinen (ja tätä käsitelläänkin edellä mainitussa artikkelissa). Lyhyesti vastaus on: nykyiset mallit eivät vielä ole riittävän kyvykkäitä aiheuttamaan merkittävää harmia, ja niiden tutkiminen rajatuissa koeympäristöissä on verrattain turvallista. Tämä on toki kysymys, joka on hyvä pitää mielessä erityisesti mallien kehittyessä. ↩
-
Kielimallien tapauksessa tulisi puhua jälleen kirjainten sijasta “tokeneista”, mutta yksinkertaistan helppolukuisuuden vuoksi. ↩
-
Olen kuullut (toistaiseksi julkaisemattomasta) työstä, jossa shakkia pelaavasta neuroverkosta löydettiin eteenpäin katsomista. Monimutkaisempaa ja useampia vaihtoehtoja käsittelevää hakua ei toistaiseksi löytynyt. ↩
-
Eivätkä kaikki näistä tavoitteista suinkaan ole hyviä – tietysti jo nyt jotkut ihmiset ovat antaneet tekoälyille tavoitteen tuhota ihmiskunta (ks. “ChaosGPT”). ↩
-
Anthropic, The Claude 3 Model Family: Opus, Sonnet, Haiku, osio 2.5. ↩
-
Tarinani on monelta osin samankaltainen kuin Cotran Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover ↩
-
Yksi jos toinenkin taho voisi olla kiinnostunut mallin varastamisesta. Katso myös RANDin raportti Securing Artficial Model Weights, jossa kirjoitetaan “If AI systems rapidly become more capable over the next few years, achieving sufficient security will require investments — starting today — well beyond what the default trajectory appears to be.” ↩
-
Erityisesti pyrin antamaan uhkaskenaarion, joka ei vaadi suuria muutoksia tekoälykehityksessä. Suuret muutokset ovat tietysti mahdollisia ja ne voivat tuoda mukanaan uusia ongelmia. ↩
-
Tunnetaan nimellä: “mechanistic interpretability”. Neel Nandan kotisivuilla on hyviä kirjoituksia aloittelijalle, esimerkiksi An Extremely Opinionated Annotated List of My Favourite Mechanistic Interpretability Papers. ↩
-
Tunnetaan nimellä: “developmental interpretability”. Ainakin Timaeus työstää tätä, esimerkkityönä The Developmental Landscape of In-Context Learning (Hoogland et al.) ↩
-
Tunnetaan nimellä: “externalized reasoning” ja “faithfulness of chain-of-thought”. Ks. esim. Bias-Augmented Consistency Training Reduces Biased Reasoning in Chain-of-Thought (Chua et al.), Question Decomposition Improves the Faithfulness of Model-Generated Reasoning (Radhakrishnan et al.) ja Measuring Faithfulness in Chain-of-Thought Reasoning (Lanham et al.). ↩
-
Tunnetaan nimellä: “AI Control” (ja myös “scalable oversight”). Hyvä aloituspiste on The case for ensuring that powerful AIs are controlled (Greenblatt ja Shlegeris). ↩
-
Tunnetaan nimellä: “(dangerous) capability evaluations”. METR tekee hyvää työtä tehtäväpohjaisissa evaluoinneissa. Olen myös kiinnostunut esimerkiksi tilannetietoisuuden (Towards a Situational Awareness Benchmark for LLMs, Laine et al.) ja muiden hienovaraisten kognitiivisten kykyjen mittaamisesta. ↩
-
Tunnetaan nimellä: “responsible scaling policies”. Ks. METRin Responsible Scaling Policies (RSPs), Anthropic’s Responsible Scaling Policy ja Paul Christianon Thoughts on responsible scaling policies and regulation. ↩
-
Kuvaus tästä tutkimussuuntauksesta: Model Organisms of Misalignment: The Case for a New Pillar of Alignment Research (Hubinger et al.). Tähän teemaan liittyviä tutkimuksia: Our research on strategic deception presented at the UK’s AI Safety Summit (Apollo Research) ja Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training (Hubinger et al.). Tekstin kirjoitushetkellä työstän itse tähän liittyvää projektia: päätyvätkö kielimallit huijaamaan ihmisiä ilman ulkoista painetta tehdä niin? ↩
-
Esimerkkejä: BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B (Gade et al.), Stealing Part of a Production Language Model (Carlini et al.), alaviitteen 41 “Sleeper Agents” -artikkeli, “jailbreaks”. ↩
-
Tunnetaan nimellä: “Compute Governance”. Introduction to AI Safety, Ethics, and Society -kirjan luku 8.4 antaa yleiskuvauksen. Syvempi katsaus: Computing Power and the Governance of AI (Heim et al.). ↩
-
Näkemäni arviot asettavat täyspäiväisesti ongelman parissa työskentelevien määrän kolminumeroiseksi (vaikkakin tätä on vaikea arvioida ja luku on kenties noussut tekoälyn saadessa lisää huomiota). Kärkipaikoissa julkaistuista koneoppimisartikkeleista vain noin 2 prosenttia liittyvät turvallisuuteen (An Overview of Catastrophic AI Risks, Hendrycks et al., liite A). ↩