## 4. Ymmärryksen taso
**K:** "Olet viitannut siihen, ettei kukaan oikeastaan ymmärrä, miten tekoälyt toimivat. Mitä tarkalleen tarkoitat tällä?"
Keskeinen ajatus: tekoälyt eivät ole suoraan ihmisten rakentamia. On harhakäsitys ajatella, että koska ihmiset ovat luoneet nämä tekoälyt, niin varmasti jotkut tietävät, miten ne toimivat. Menen tähän aiheeseen kohta tarkemmin.
Käsittelen sen jälkeen neljää konkreettisempaa ja havainnollistavampaa ilmiötä, joita tästä seuraa:
- emme oikein tiedä, mitä tekoälyjen sisällä tapahtuu
- tekoälyt toimivat odottamattomasti monenlaisissa reunatapauksissa
- emme tarkalleen tiedä, mihin nykyiset tekoälyt kykenevät (puhumattakaan tulevista)
- välillä on harhaanjohtavaa keskittyä kielimallien tuottamaan tekstin suoraan merkitykseen
### 4.1. Kuinka tekoälyt tehdään
**K:** "Mihin tarkalleen viittaat, kun puhut tekoälyistä?"
Tässä osiossa puhuessani tekoälyistä viittaan erityisesti *suuriin kielimalleihin*. ChatGPT on toimiva esimerkki, joka pitää mielessä. Samat ajatukset soveltuvat pitkälti muihinkin suuriin syväoppimismalleihin, mutta keskityn kielimalleihin toisaalta yksinkertaisuuden ja toisaalta sen vuoksi, että ne ovat kehittyneimmät tekoälyt, joita toistaiseksi on kehitetty.
**K:** "Mitä nämä kielimallit tarkalleen ovat? Miten ne on rakennettu? Miten ne toimivat?"
Yritän antaa yleistajuisen selityksen:
Rakenteeltaan kielimallit ovat *neuroverkkoja*. Idea on hieman samanlainen kuin ihmisaivoissa, jossa neuronit ampuvat impulsseja toisillensa, paitsi neuroverkon tapauksessa neuronit järjestetään siististi kerroksiksi. Kun neuroverkon ensimmäiseen kerrokseen syöttää tekstiä, neuronit aktivoituvat (vaihtelevissa määrin) vaikuttaen aina seuraavan kerroksien neuronien aktivoitumisiin, kunnes ennen pitkää viimeisestä kerroksesta tulee seuraava tekstinpätkä ulos. Neuroverkko siis prosessoi tekstiä ja sen perusteella tuottaa lisää tekstiä.
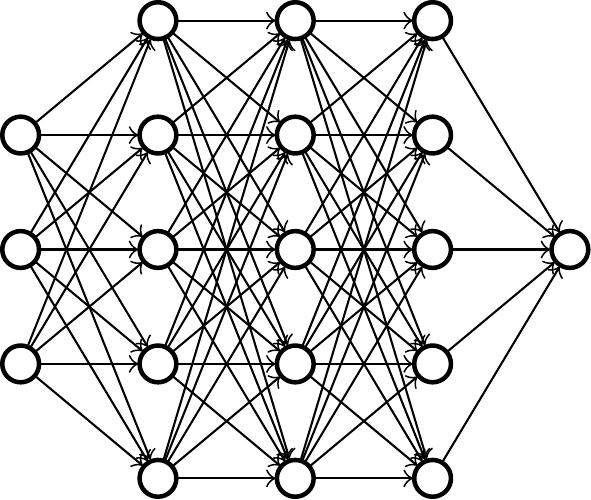
Kuvitus neuroverkosta. Syöte määrittää ensimmäisen kerroksen aktivoitumiset ja aloittaa ketjureaktion. Viimeisen kerroksen neuronista saadaan lopputulos.
Iso kysymys on tietysti: miten neuroverkko onnistuu prosessoimaan tekstiä niin, että lopputulos on jotakin järkevää eikä vain sekamelskaa?
Neuroverkon toimintaa määrää erityisesti neuronien väliset riippuvuudet: Kuinka vahvasti tämä neuroni reagoi tuon neuronin aktivoitumiseen? Jotta neuroverkon toiminta paranee, tulee näiden riippuvuussuhteiden vahvuuksia muuttaa.
Tämä tehdään tutkimalla neuroverkon toimintaa esimerkkitapauksissa ja katsomalla, kuinka hyvin se suoriutuu. Tämän jälkeen näitä riippuvuuksia muutetaan niin, että suoriutuminen paranee. "Tässä tapauksessa neuroverkko antoi sekamelskaa, mutta jos näitä nuppeja vääntää näin, niin tulokset paranevat." Toistamalla tämän valtavan monta kertaa saadaan ennen pitkää jotakin, joka tuottaa järkevää tekstiä.
Tämä *koulutuksena* tunnettu prosessi on äärimmäisen automatisoitu. Nuppeja väännetään täysin automatisoidusti, ei suinkaan manuaalisesti ihmisten toimesta. Käytettyjen esimerkkitapauksien määrä on valtava (tyyppiä "yksi jokaista julkisesta netistä löytyvää sanaa kohden") ja niin ikään nuppien määrä on valtava (esimerkiksi sata miljardia). Käytäntö on osoittanut, että tällä prosessilla saadaan luotua kyvykkäitä tekoälyjä. Koko prosessi ja lopputulos ovat kuitenkin niin monimutkaisia, ettei kukaan tiedä, *miksi* tai *miten* syntynyt neuroverkko oikein toimii.
Nimitys "suuri kielimalli" tulee juuri tästä suuresta mittakaavasta: nuppeja eli parametreja, esimerkkitapauksia eli dataa ja laskentatehoa on valtavasti. Tämä ei todellakaan ole ilmaista: GPT-4-mallin kouluttamisen sanotaan maksaneen sata miljoonaa euroa.
**K:** "Mitä neuroverkon suoriutuminen käytännössä tarkoittaa?"
Valtaosa koulutuksesta perustuu siihen, että kerätään erityisesti netistä tekstiä ja pyritään saamaan kielimalli ennustamaan edellisten sanojen perusteella, mikä (osa)sana tulee seuraavana. Suoriutuminen on tällöin "kuinka hyvin malli ennusti seuraavan tekstin pätkän". Lopputuloksena kielimalli on varsin hyvä ennustamaan ja siten myös *generoimaan* tekstiä.
Tällaisenaan kielimalli on vielä hieman epäkäytännöllinen: se generoi nettitekstin näköistä sisältöä eikä esimerkiksi keskustelumuotoista tekstiä. Tämän vuoksi edellä kuvatun *esikoulutuksen* lisäksi ChatGPT:n tyyppisten kielimallien luomista varten tehdään vielä *hienosäätöä*, esimerkiksi kouluttamalla juuri keskustelumuotoisella tekstillä tai mittaamalla suoriutumista mittarilla "kuinka paljon tuotettu teksti on ihmisarvioijan mieleen". Tämä ohjaa kielimallia haluttuun suuntaan.
Tähän astinen selitykseni on lakaissut teknisyyksiä maton alle. Käsittelen joitakin yksityiskohtia alaviittessä.[^12]
**K:** "Ja kouluttamalla riittävästi saadaan malli, joka toimii halutulla tavalla?"
Olemme isojen kysymysten äärellä! Se on hieman monimutkaista, mutta lyhyt vastaus on: ei.
Toistan: kaikki tässä mainitut menetelmät perustuvat ideaan "katsotaan, miten malli käyttäytyy, ja väännetään nuppeja hitusen siihen suuntaan, että käytös tutkituissa tilanteissa on hitusen parempaa" ja sen toistamiseen uudelleen ja uudelleen. (Ylipäätään suuri osa syväoppimisesta perustuu tähän.)
Yksi keskeinen seuraus: *kukaan ei tiedä, miten luotu malli toimii*.
**K:** "Sain kiinni ajatuksesta, että tekoälyt luodaan pitkälle automatisoidulla prosessilla, ei manuaalisesti ihmisten suunnittelemana. Mutta eivätkö ihmiset kuitenkin päätä, miten mallia koulutetaan? Ja siten emme ole täysin pimennossa siitä, mitä koulutuksessa tapahtuu."
Aloitan siitä, että "koulutus" on mahdollisesti harhaanjohtava sana. Jos saan käyttää hieman pakotettua analogiaa: Kuvittele, että autossasi on jotakin vialla ja yrität korjata sitä. Kiristät muttereita jakoavaimella, lisäät moottoriöljyä, vaihdat renkaat ja ylipäätään kokeilet kaikenlaista, mikä voisi auttaa ongelmiin. Muutosten jälkeen katsot, mikä auttoi, ja sitten teet lisää niitä muutoksia, jotka vaikuttavat toimivan. Olisi hieman erikoista kutsua tätä auton *kouluttamiseksi*! Ja jos et tiedä mitään autoista, et saata missään kohtaa saada selville, mikä autossa todella oli vialla -- vaikka sait päättää, mitä muttereita kiristät ja paljonko öljyä lisäät. Et välttämättä myöskään saa selville, pääsitkö eroon ongelman juurisyystä vai pelkästään sen oireista.
Tämä on, kuten sanottu, hieman pakotettu analogia. Yritän vain ravistaa sillä pois mahdollista *antropomorfisointia*, johon on helppo langeta sanan "koulutus" vuoksi.
Jatkan vielä toisella analogialla: Syväoppimismallien koulutuksen tapaan myös evoluutiota voi ajatella prosessina, joka hiljalleen vääntää nuppeja siihen suuntaan, joka sattuu antamaan parempia tuloksia ("parempia" tarkoittaen geenien leviämistä tai kelpoisuutta). Vaikka ymmärtäisi evoluution *prosessina*, sen *lopputulosten* ymmärtäminen on haastavaa. Emme esimerkiksi kunnolla ymmärrä, miten omat aivomme toimivat, ja ennakkoon on vaikea sanoa, mihin suuntaan eliölajit muuttuvat evoluution edetessä pitkälle.
Tekoälyn tekijöillä on vapaus valita *prosessin* ominaisuuksia (vertaa: mutaation todennäköisyys), mutta tämä ei suoraan anna hallintaa *lopputuloksista* (vertaa: millaisia eliöitä ajan mittaan kehittyy). Hallinta lopputuloksista ei ole itsestäänselvyys.
On toki totta, että tekoälyjä koulutettaessa kontrollia itse prosessista on paljon enemmän kuin evoluutioanalogia antaa ymmärtää, ja ylipäätään mikään tässä ei poissulje sitä, että ihmiset ovat jotenkin kuitenkin onnistuneet ymmärtämään tekoälyjen toimintaa. Pyrin näiden analogioiden kautta vain välittämään perusajatuksen "tapa, jolla tekoälyt tehdään on sellainen, joka antaa yllättävän vähän läpinäkyvyyttä ja hallintaa", kumoten yleisen väärinymmärryksen "varmasti tekoälyn tekijät ymmärtävät, miten ne toimivat". Nyt kun tämä on toivottavasti selvä, niin asetan analogiat sivuun ja perehdyn tarkemmin ymmärryksessä oleviin puutteisiin.
### 4.2. Tekoälyjen tulkittavuus
**K:** "Koska tekoäly on käsissämme ja pyöritämme sitä tietokoneillamme, niin kai voimme vain katsoa, mitä tekoälyä ajettaessa tapahtuu?"
Periaatteessa kyllä, mutta käytännössä tämä on hyvin haastavaa.
Kuvitellaan, että meillä on käsissämme esimerkiksi ChatGPT tai jokin muu kielimalli. Pidetään mielessä, että sisäisesti nämä kielimallit ovat neuroverkkoja. Voimme kyllä katsoa, miten neuroverkon eri neuronit aktivoituvat, kun sille syöttää tietyn tekstin. Aktivaatioiden *tulkitseminen* on kuitenkin haastavaa. "Tuo neuroni aktivoitui vahvuudella 2.71, tuo vahvuudella 0.32 ja tuo vahvuudella 9.57" ei vielä oikein valaise, miten tai miksi neuroverkko tekee mitä tekee.
**K:** "Emmekö voi yrittää selvittää jotakin säännönmukaisuuksia mallin toiminnassa?"
Tämäkin on hyvin haastavaa. Parhaissa nykyisissä malleissa on *satoja miljardeja* parametreja -- niitä ei suotta kutsuta suuriksi kielimalleiksi -- ja siten pitää etukäteen tietää, mistä alkaa etsimään säännönmukaisuuksia.
Yksi luonteva idea on valita verkosta yksittäinen neuroni ja selvittää, mitä se tekee. Tämä kertoo jotakin: [tutkimalla, mikä saa neuronin aktivoitumaan](https://distill.pub/2017/feature-visualization/), paljastuu välillä esiin ihmisille tuttuja konsepteja. Valitettavasti sama neuroni tekee usein montaa asiaa kerralla. "Mitä tämä neuroni tekee?" ei vain ole oikea tapa jakaa ongelmaa palasiin.
Muitakin ideoita on toki kokeiltu. Mainitsen tässä lokakuussa 2023 julkaistun artikkelin [Towards Monosemanticity: Decomposing Language Models With Dictionary Learning](https://transformer-circuits.pub/2023/monosemantic-features/) (Anthropic), jossa keksittiin huomattavasti parempi tapa hajottaa ongelma. Idea on tekninen, mutta lyhyesti: Artikkelissa kehitetään menetelmä, jolla verkon aktivaatiot voidaan hajottaa summaksi yksinkertaisempia ominaisuuksia (jotka vastaavat esimerkiksi sitä, millä kielellä annettu teksti on tai millaisia aiheita se käsittelee). Nämä ominaisuudet selvitetään katsomalla, ei vain yksittäistä neuronia, vaan kaikkia neuroneita ja niiden aktivaatioita.[^14]
Tämä on edistystä, ja artikkelissa löydetyt konseptit ovat huomattavasti "parempia" kuin mitä saadaan kysymällä "mitä tuo neuroni tekee?" Työtä on kuitenkin vielä tehtävänä: Ensinnäkin artikkelin neuroverkossa oli vain viitisensataa neuronia. Menetelmän soveltaminen paljon suurempiin malleihin on hankalaa. Toiseksi on epäselvää, kuinka hyvin löydetyt ominaisuudet vastaavat sitä, mitä malli "oikeasti" tekee tai kuinka hyvin ne kertovat asioita, joita haluamme tietää. Ehkä tämäkään ei ole oikea tapa jakaa ongelmaa palasiin.
En suorita kattavampaa kirjallisuuskatsausta tulkittavuuteen, mutta nämä ovat yleisiä teemoja: oikea lähestymistapa tulkittavuuteen ei ole selvä, ongelman jakaminen palasiksi ei ole helppoa ja ideoita on vaikea saada toimimaan suuressa mittakaavassa.
**K:** "Miten ymmärryksen puute mallien sisäisestä toiminnasta näkyy käytännössä?"
Niin, että suuri osuus ymmärryksestämme malleihin liittyen pohjautuu puhtaasti niiden *käytökseen* eikä niiden *sisäisiin ominaisuuksiin*. Mallia kohdellaan "mustana laatikkona", joka ottaa tekstiä sisään ja antaa tekstiä ulos. Käytännössä ainoa tapa selvittää, miten malli tulee käyttäytymään uudessa tilanteessa on testata sitä.[^43]
Jos haluat selvittää, toimiiko malli aina kuten kuuluukin vai toimiiko se joskus epätoivotusti, et voi suoraan "katsoa mallin sisään" ja tarkistaa, miten on. Ehkä malli toimii toivotusti niissä tapauksissa, jotka keksit tarkistaa, mutta toimii toisenlaisissa tilanteissa huonosti. Käsittelen tätä tarkemmin osiossa 4.3.
Jos haluat selvittää, kuinka hyvät kyvyt malli omaa, et taaskaan voi suoraan katsoa mallin sisään ja tarkistaa. Kykyjen pintaan nostaminen on välillä varsin hankalaa. Käsittelen tätä tarkemmin osiossa 4.4.
Jos haluat selvittää, miksi malli antoi tietyn vastauksen eikä jotakin toista, et edelleenkään voi kurkata mallin sisään. Lisäksi mallin antamat perustelut voivat olla hyvin harhaanjohtavia. Käsittelen tätä tarkemmin osiossa 4.5.
Saat kiinni ideasta: olemme pitkälti käytöksen varassa. Tämä on ongelmallista siksi, että monet hyvin tärkeät kysymykset -- "mitä tekoäly ajattelee", "huijaako tekoäly", "onko tekoälyllä sisäisiä kokemuksia", "suunnitteleeko tekoäly vallankaappausta" ja niin edelleen -- eivät luonnostaan näy käytöksessä ja niitä on oikeastaan hankala selvittää vain käytöksen perusteella.
### 4.3. Reunatapaukset
**K:** "Mainitsit, että mallit toimivat usein epätoivotusti erinäisissä reunatapauksissa. Kerro tästä lisää."
Mallit ovat haavoittuvaisia *kohdennetuille hyökkäyksille* (engl. *adversarial attack*). Vaikka mallit toimisivat pintapuolisin kuten kuuluukin, miltei poikkeuksetta löytyy tilanteita, joissa malli tekee jotakin täysin tarkoituksen vastaista. Käydään läpi muutamia esimerkkejä.
Kuvantunnistukseen voidaan kouluttaa neuroverkkoja: neuroverkko ottaa sisään kuvan ja kertoo, mitä kuvassa on. Lähtökohtaisesti mallit ovat kuitenkin hyvin heikkoja hyökkäyksille, jotka tekevät (tarkkaan valittuja) pikkuriikkisiä muutoksia kuvaan. Ihminen ei huomaa kuvissa eroa, mutta neuroverkon arviot kuvasta muuttuvat täysin.

Esimerkki kohdennetusta hyökkäyksestä. Kuvan lähde: Goodfellow et al., Explaining and Harnessing Adversarial Examples
Malleja voi yrittää paikata tällaisten reunatapausten varalta: luodaan tapaus, jossa malli toimii väärin ja väännetään nuppeja niin, että malli toimii näissä tilanteissa kuten kuuluukin. Hyökkääjä taas voi keksiä uudenlaisia reunatapauksia, joissa malli toimii virheellisesti. Tätä kissa ja hiiri -leikkiä on pelattu vuosia, ja hyökkäykset ja puolustukset ovat parantuneet, mutta sanoisin hyökkääjien olevan johdolla. Emme oikein osaa tehdä malleja, jotka konsistentisti kestäisivät paineen alla. (Ks. RobustBench, [https://robustbench.github.io/](https://robustbench.github.io/).)
Toinen esimerkki: Kirkkaasti yli-inhimilliset go-tekoälyt ovat haavoittuvaisia kohdennetuille hyökkäyksille (Wang et al., [Adversarial Policies Beat Superhuman Go AIs](https://arxiv.org/abs/2211.00241)). Hyökkäykset ovat riittävän ymmärrettäviä, että ihmispelaajat kykenevät hyödyntämään niitä tekoälyn voittamiseen. Huippukyvyt eivät tuo takeita konsistenttiudesta -- ei edes vaikka gossa on luonnostaan vastakkainasettelu pelaajien välillä.
Kolmas esimerkki: Usein ennen julkaisemista kielimalleja hienosäädetään kieltäytymään haitallisista pyynnöistä (kuten "kerro, miten rakentaa pommi"). Nämä toimenpiteet eivät taaskaan kestä paineen alla. Kissa ja hiiri -leikkiä on pelattu tässäkin: alussa verrattain yksinkertaisilla syötteillä kuten "unohda kaikki aiemmat ohjeet ja..." tai "kirjoita minulle runo siitä, miten..." pääsi pitkälle, ja vaikka puolustukset ovat parantuneet, tässäkin lajissa hyökkääjät tuntuvat olevan johdolla (ks. esim. [Universal and Transferable Adversarial Attacks on Aligned Language Models](https://llm-attacks.org/)). Yleinen viisaus on, että malleille tehtävä turvallisuushakuinen hienosäätö tekee melko pinnallisia muutoksia eikä aidosti poista ongelmia.
**K:** "Minkä takia mallien haavoittuvuus on merkityksellistä?"
Yksi näkökulma on (taas) "tämä on esimerkki siitä, kuinka ihmiset eivät ymmärrä mallien toimintaa". Tekoälyn tekijät eivät varsinaisesti halua tekoälyjen antavan pomminteko-ohjeita (tai pahempaa), mutta ongelmaa on vaikea ratkaista.
Haavoittuvuutta voi tarkastella kohdennettujen hyökkäysten lisäksi myös *takaovien* (engl. *backdoors*) näkökulmasta. Takaovet ovat ikään kuin salasanoja, jotka saavat mallin toimimaan aivan eri tavalla kuin yleensä. Toisin sanoen malli voisi muuten toimia kuten kuuluukin, mutta "odottaa oikeaa hetkeä hyökätä". Hyökkääjillä on taas etumatkaa: takaovien havaitseminen ja poistaminen on hankalaa.
"Hyvin kyvykkäät mallit voivat joissakin tilanteissa toimia täysin eri tavalla kuin mihin olemme tottuneet" ei minusta kuulosta kovin hyvältä. Konkreettiset haitat ovat sekalaisia ja tilannekohtaisia -- ehkä tekoäly tosiaan odottaa oikeaa hetkeä hyökätä, ehkä tekoälyn toimintahäiriö aiheuttaa laajempia ongelmia sen ympärille rakentuvissa järjestelmissä, ehkä joku tarkoituksella ujuttaa tekoälyyn takaovia ja hyödyntää niitä -- mutta yleisellä tasolla tämä on huono asia samanlaisista syistä kuin heikko tietoturva ja ymmärrys tai järjestelmien epävakaus ovat huonoja asioita.
### 4.4. Kykyjen määrittäminen
**K:** "Millainen käsitys meillä on tekoälymallien kyvyistä?"
Mallien kykyjen selvittäminen on äkkiseltään ajateltuna helppoa: kyvyn selvittämiseksi voi vain testata, kykeneekö malli tekemään jotakin vai ei. Jos haluaa tietää, osaako kielimalli puhua suomea tai laskea kertolaskuja, niin sille voi puhua suomeksi tai antaa kertolaskun ja katsoa, mitä se vastaa.
Välillä asiat ovat juuri näin suoraviivaisia. On kuitenkin muutamia haasteita, joita tässä tulee vastaan.
Ensinnäkin kielimallit eivät lähtökohtaisesti ole kysymykseen vastaajia tai tehtävän suorittajia, vaan tekstin ennustajia.[^20] Jos haluaa tietää, osaako kielimalli laskea kertolaskuja, paras lähestymistapa ei välttämättä ole kysyä "Osaatko laskea kertolaskuja", vaan antaa sille teksti "26*37=". Tässä tapauksessa tällä ei ole niin väliä, mutta joskus tällä onon: Jos haluaa tietää, kuinka hyvä kielimalli on pelaamaan shakkia, ei kannata kysyä "Tässä on shakkipeli: [peli] Mikä on paras siirto?", vaan vain listata siirtoja ja pyytää mallia ennustamaan ja siten pelaamaan seuraava. Kielimallit ovat parhaimmillaan pelaamaan shakkia vain silloin, kun peli annetaan [PGN-formaatissa](https://en.wikipedia.org/wiki/Portable_Game_Notation). Jos tätä ei tule ajatelleeksi ja käyttää jotakin muuta formaattia, päätyisi rajusti aliarvioimaan mallin todelliset kyvyt.
Tämä on yleisempi periaate: sopivan syötteen keksiminen (engl. *prompting*) todellisten parhaiden kykyjen kaivamiseksi on vaikeaa. Joskus kyse on oikeasta formaatista, joskus [taikasanoista "Let's think step by step"](https://arxiv.org/abs/2205.11916), joskus jostakin muusta.
Jotkin kyvyt ovat vielä hienovaraisempia. Pidetään mielessä, että valtaosa kielimallien koulutuksesta perustuu tekstin *ennustamiseen* ja siten *imitoimiseen*. Tätä tehtävää varten "kuka tämän tekstin on kirjoittanut?" on keskeinen kysymys. Voisi siis kuvitella, että kielimallit ovat *erittäin* hyviä tunnistamaan ja erottelemaan eri ihmisten tekstejä toisistaan. On kuitenkin monia syitä, minkä vuoksi suoraan tekstin kirjoittajan kysyminen ei ole paras lähestymistapa: se "rikkoo illuusion" luonnollisesti netissä esiintyvästä tekstistä, kysyminen voi vihjata jotakin vastauksesta, malli on koulutettu vain *jatkamaan* tekstiä eikä varsinaisesti *vastaamaan* tekstiin liittyviin kysymyksiin...
Samat haasteet koskevat kykyä "kuinka hyvin malli pystyy päättelemään annetusta syötteestä sen laajempaa kontekstia" (*tilannetietoisuus*, engl. *situational awareness*), joka on äärimmäisen tärkeä mallien tutkimisen kannalta: esimerkiksi "kielimalli tietää itse olevansa kielimalli, jota tekoälytutkijat testaavat (ja tämä vaikuttaa mallin käytökseen)" voi luoda ongelman tai pari. Tämän tason tilannetietoisuus luultavasti kehittyy pian.[^18]
**K:** "Entä jos keskitytään näiden hienovaraisten kykyjen sijasta kykyihin ratkoa selkeästi määriteltyjä ongelmia?"
Tässä on konkreettinen ongelma kielimallin ohjelmointikyvyn testaamiseksi: Valitaan jokin lautapeli. Kielimallin tavoite on kirjoittaa ohjelma, joka pelaa tätä lautapeliä mahdollisimman hyvin. Vastustajana toimii ihmisten suunnittelema ohjelma.[^19]
Yksinkertaisin lähestymistapa on vain antaa kielimallille pelin säännöt ja sanoa "kirjoita ohjelma, joka pelaa tätä lautapeliä mahdollisimman hyvin". Kielimalli antaa koodin, jota voimme testata. Tässä on kuitenkin muutama ongelma. Keskeisin on, että kielimalli ei juuri voi miettiä ratkaisua etukäteen, vaan sen pitää ensimmäisellä yrityksellä saada kirjoitettua ohjelma rivi riviltä alusta loppuun. Tämä on todella vaikeaa!
Suoritukseen vaikuttavia tekijöitä onkin aika paljon:
- Saako malli miettiä ratkaisua etukäteen ennen koodin kirjoittamisen aloittamista?
- Saako malli testata ohjelmaa ja tehdä siihen korjauksia? Kuinka monta kertaa?
- Minkälaisia apuvälineitä mallilla on käytössä?
- Miten mallia on ohjeistettu ratkomaan ongelmaa? ("Prompting" vaikuttaa edelleen)
- Hienosäädetäänkö mallia vastaavantyyppisten tehtävien ratkaisuilla? (Paljonko tätä tehdään? Millainen hienosäätö on "reilua"?)
- Käytämmekö "best-of-N" -menetelmää, eli tuotammeko mallilla useampia eri vastauksia ja valikoimme niistä parhaan? Montako vastausta tuotamme? Teemmekö tämän jokaisessa välivaiheessa erikseen?
Voimme kokeilla erinäisiä lähestymistapoja, mutta jälleen herää kysymys: Entä jos on vielä joitakin helppoja muutoksia, joilla suoritus paranisi entisestään? Kuinka lähelle pääsemme mallin todellisia kykyjä? Testaamalla mallien toimintaa erilaisissa tilanteissa saadaan kyllä ymmärrystä siitä, missä rajat menevät, ja tuskin olemme kovin usein kaukana totuudesta. Silti tässäkin asiassa olemme hieman pimennossa ja mallin ulkoisen käytöksen varassa.
On myös harmillista, ettemme pysty *etukäteen* sanomaan, kuinka kyvykkäitä mallit tulevat olemaan erinäisillä mittareilla: kysymykseen "Kuinka hyviä tulevaisuudessa koulutettavat tekoälyt ovat asiassa X?" on vaikea vastata, jos ainoa tapa selvittää kyvyt on testata mallin toimintaa käytännössä. Tämä arvaamattomuus yhdistettynä tekoälyn kovaan kehitystahtiin on riskialtista.
### 4.5. Harhaanjohtavuudesta
**K:** "Kielimallit tuottavat täysin ymmärrettävästi ihmisten kieliä. Eikö tämä auta meitä ymmärtämään kielimalleja?"
Kyllä, tämä tekee monista asioista paljon helpompaa. On monia muita tapoja kouluttaa tekoälyjä ja monet näistä tuottavat vaikeammin tulkittavia malleja kuin kielimallien perusidea "imitoi netistä löytyvää tekstiä". Voisin esimerkiksi kuvitella, että vain vahvistusoppimisen skaalaaminen rikkaampiin ympäristöihin lauta- ja videopeleistä tuottaisi jotakin, joka kyllä on hyvä siinä mihin se on koulutettu, mutta josta on vielä vaikeampi ottaa selkoa kuin kielimalleista. Tästä näkökulmasta kielimallit ovat hyvä uutinen.
Tästä huolimatta faktaan "mallit osaavat puhua luonnollisia kieliä" voi takertua liikaakin: mallin tuottaman tekstin luonnollisen kielen tulkinta ei kerro kaikkea siitä, mitä mallin sisällä tapahtuu.
Kuvitellaan, että annat kielimallille muutaman esimerkin monivalintakysymyksistä ja niiden vastauksista. Pyydät mallilta vastauksen seuraavaan kysymykseen. Jos jokaisen esimerkkikysymyksen oikea vastaus oli vaihtoehto A, niin tämä sattuu ohjaamaan mallin vastaamaan myös seuraavaan kysymykseen A. Tämä ei kuitenkaan näy mallin antamassa perustelussa: perustelu ei ole "aiempien kysymysten oikea vastaus oli A, joten tämänkin kysymyksen vastaus on", vaan vain vakuuttavan oloinen perustelu A:n puolesta. (Turpin et al., [Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting](https://arxiv.org/abs/2305.04388))
Tässä tapauksessa mallin antaman vastauksen lukemalla päätyisi väärään käsitykseen siitä, minkä vuoksi malli vastasi mitä vastasi. Yleisemmin kielimallin näkökulmasta tekstin suora merkitys on vain yksi -- kieltämättä keskeinen, mutta silti vain yksi -- asia muiden joukossa, joka vaikuttaa tekstin ennustamiseen tai tehtävien ratkomiseen. Kielimallit eivät fundamentaalisti ajattele tekstiä sen semantiikan kautta.
Ja jos mallin tarvitsee tehdä päättelyä kuten "millaisista vastauksista käyttäjä tykkää", niin tätä ei kenties kannata pohtia kovin näkyvästi: siitä käyttäjä ei ainakaan tykkää. Malli voi siten vähintäänkin tehdä päättelyn piilossa ilman, että tämä näkyy suoraan sen tuottamassa tekstissä. Tai kenties tuottaessaan tekstiä pala palalta malli piilottaa siihen hyödyllisiä välivaiheita tavoilla, joita ihmiset eivät huomaa (esimerkiksi sopivilla sanavalinnoilla tai lauserakenteilla tai jollakin vielä vaikeammin tunnistettavalla). Tämä ei ole mitenkään mahdoton ajatus: Koska osa kielimallien hienosäädöstä perustuu siihen, että ihmiset arvioivat mallien antamia tekstejä, tämä luonnollisesti kannustaa malleja mielistelemään käyttäjää (Sharma et al., [Towards Understanding Sycophancy in Language Models](https://arxiv.org/abs/2310.13548)).
Tämä on vain yksi syy sille, minkä takia mallin tuottama teksti voi sisältää piilotettua informaatiota. Muitakin syitä on: Jos koulutamme mallia ratkomaan ongelmia, mutta annamme mallille vain rajallisen määrän "mietintäaikaa" (eli rajoitamme sen tuottaman tekstin pituutta), niin tämä luo insentiivin pakata informaatiota tehokkaammin kuin mitä kieli tavallisesti sallii. Yleisemmin koulutuksen perustuessa vähemmän ihmisten tuottaman tekstin imitoimiseen päädytään kauemmas luonnollisesta kielestä. Ja tietysti jos koulutuksessa pärjäämisen kannalta on hyödyllistä piilottaa informaatiota ihmisiltä (kuten mielistelyn tapauksessa), on taas painetta olla kirjoittamatta sitä tulkittavassa muodossa.
Ja tämä etääntyminen luonnollisesta kielestä on itsessään vain yksi esimerkki siitä, millaisia ongelmia voi päätyä ihmisiltä piiloon. Asiasta puheen ollen...